Hasta ahora hemos visto como podemos recuperar los datos de la petición HTML. También hemos visto como podemos leer un archivo con el módulo 'fs'.
En este concepto nos concentraremos en como dada una petición de una página HTML proceder a verificar si existe dicha página, leerla y retornarla al navegador que la solicitó.
Vamos a crear un subdirectorio llamado 'static' (puede tener cualquier nombre) en la carpeta donde crearemos nuestra aplicación Node.js y almacenaremos tres páginas HTML: index.html, pagina1.html y pagina2.html
El contenido de estos tres archivos será:
index.html
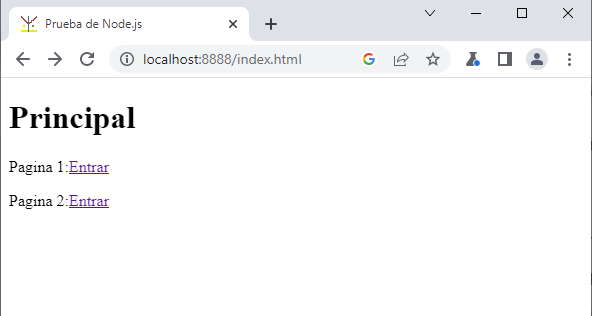
<!doctype html> <html> <head> <title>Prueba de Node.js</title> <meta charset="UTF-8"> </head> <body> <h1>Principal</h1> <p>Pagina 1:<a href="pagina1.html">Entrar</a></p> <p>Pagina 2:<a href="pagina2.html">Entrar</a></p> </body> </html>
pagina1.html
<!doctype html> <html> <head> <title>Prueba de Node.js</title> <meta charset="UTF-8"> </head> <body> <h1>Pagina 1</h1> <p><a href="index.html">Retornar</a></p> </body> </html>
pagina2.html
<!doctype html> <html> <head> <title>Prueba de Node.js</title> <meta charset="UTF-8"> </head> <body> <h1>Pagina 2</h1> <p><a href="index.html">Retornar</a></p> </body> </html>
Tener bien en cuenta de grabar estos tres archivos HTML en una subcarpeta llamada static.
Ahora creemos nuestro programa en Node.js que se encargará de responder a peticiones de páginas HTML.
Creemos el archivo (no debe estar dentro de la carpeta static, sino en la carpeta padre):
ejercicio9.js
const http = require('node:http')
const fs = require('node:fs')
const servidor = http.createServer((pedido, respuesta) => {
const url = new URL('http://localhost:8888' + pedido.url)
let camino = 'static' + url.pathname
if (camino == 'static/')
camino = 'static/index.html'
fs.stat(camino, error => {
if (!error) {
fs.readFile(camino, (error, contenido) => {
if (error) {
respuesta.writeHead(500, { 'Content-Type': 'text/plain' })
respuesta.write('Error interno')
respuesta.end()
} else {
respuesta.writeHead(200, { 'Content-Type': 'text/html' })
respuesta.write(contenido)
respuesta.end()
}
})
} else {
respuesta.writeHead(404, { 'Content-Type': 'text/html' })
respuesta.write('<!doctype html><html><head></head><body>Recurso inexistente</body></html>')
respuesta.end()
}
})
})
servidor.listen(8888)
console.log('Servidor web iniciado')
Lo primero que hacemos es requerir los módulos 'http', y 'fs' que hemos analizado en conceptos anteriores:
const http = require('node:http')
const fs = require('node:fs')
Procedemos a crear un servidor de peticiones HTTP, tema ya visto:
const servidor = http.createServer((pedido, respuesta) => {
....
});
En la función anónima creamos un objeto de la clase URL como vimos en el concepto anterior:
const url = new URL('http://localhost:8088' + pedido.url)
Obtenemos las distintas partes de la url en un objeto literal para facilitar extraer solo el camino y nombre del archivo HTML.
Inicializamos una variable con el nombre de la subcarpeta que contiene los archivos HTML y le concatenamos el camino y nombre del archivo HTML solicitado:
let camino = 'static' + url.pathname
Por ejemplo podrían ser:
static/ static/index.html static/pagina1.html static/pagina2.html
También podrían ser peticiones de páginas que no existen, por ejemplo:
static/pagina5.html static/carpeta1/pagina1.html etc.
El primer control que hacemos es verificar si en la url no viene ninguna página, en dicho caso retornamos el archivo index.html que es el principal del sitio, para verificar hacemos un if:
if (camino == 'static/')
camino = 'static/index.html'
Por ejemplo si disponemos:
http://localhost:8888/ o http://localhost:8888
Estaríamos para este caso retornando el archivo index.html.
Mediante el objeto fs procedemos a verificar si existe el archivo HTML, el método stat tiene como primer parámetro el nombre del archivo que debemos indicarlo con todo el camino y el segundo parámetro es una función anónima que llega como parámetro si hubo o no un error con la existencia del archivo:
fs.stat(camino, error => {
if (!error) {
....
} else {
....
}
Veamos primero si no existe el archivo, en dicho caso se ejecuta el else del if y procedemos a devolver al navegador un mensaje y el código 404 de recurso inexistente (el parámetro error llega un null si no existe el archivo):
fs.stat(camino, error => {
if (!error) {
...
} else {
respuesta.writeHead(404, {'Content-Type': 'text/html'})
respuesta.write('<!doctype html><html><head></head><body>Recurso inexistente</body></html>');
respuesta.end()
}
Veamos que sucede si el if se verifica verdadero, es decir si existe el archivo HTML:
fs.stat(camino, error => {
if (!error) {
fs.readFile(camino, (error,contenido) => {
if (error) {
respuesta.writeHead(500, {'Content-Type': 'text/plain'})
respuesta.write('Error interno')
respuesta.end()
} else {
respuesta.writeHead(200, {'Content-Type': 'text/html'})
respuesta.write(contenido)
respuesta.end()
}
})
} else {
...
}
Si existe el archivo procedemos a llamar al método readFile para leer su contenido. El método readFile tiene dos parámetros, el primero es el nombre del archivo HTML a leer (que debemos indicar siempre todo el path) y el segundo parámetro es una función anónima que tiene dos parámetros que son si hubo error y el contenido del archivo:
fs.readFile(camino, (error,contenido) => {
....
})
Cuando se ejecuta la función anónima que ocurre luego de traer a memoria el contenido del archivo verificamos si no hubo un error en la lectura y en caso negativo procedemos mediante el objeto 'respuesta' a devolver al navegador el contenido completo del archivo indicando que se trata de un archivo HTML:
fs.readFile(camino, (error,contenido) => {
if (error) {
.....
} else {
respuesta.writeHead(200, {'Content-Type': 'text/html'})
respuesta.write(contenido)
respuesta.end()
}
})
Si hubo error interno en el servidos cuando se lee el archivo HTML procedemos a retornar el código 500 para que el navegador conozca tal situación (tengamos en cuenta que el archivo existe pero por algún motivo luego de verificar que existía no se ha podido leer):
fs.readFile(camino, (error,contenido) => {
if (error) {
respuesta.writeHead(500, {'Content-Type': 'text/plain'})
respuesta.write('Error interno')
respuesta.end()
} else {
.........
}
})
Implementación alternativa empleando el módulo 'fs/promises'
ejercicio9b.js
const http = require('node:http')
const fs = require('node:fs/promises')
const servidor = http.createServer((pedido, respuesta) => {
const url = new URL('http://localhost:8888' + pedido.url)
let camino = 'static' + url.pathname
if (camino == 'static/')
camino = 'static/index.html'
fs.stat(camino)
.then(() => {
fs.readFile(camino)
.then(contenido => {
respuesta.writeHead(200, {'Content-Type': 'text/html'})
respuesta.write(contenido)
respuesta.end()
})
.catch(error => {
respuesta.writeHead(500, { 'Content-Type': 'text/plain' })
respuesta.write('Error interno')
respuesta.end()
})
})
.catch(error => {
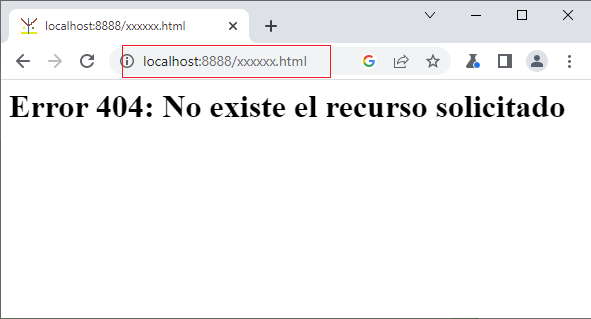
respuesta.writeHead(404, { 'Content-Type': 'text/html' })
respuesta.end('<h1>Error 404: No existe el recurso solicitado</h1>')
})
})
servidor.listen(8888)
console.log('Servidor web iniciado')
Como podemos comprobar al utilizar las funciones que retornan promesas nos permiten generar un código mucho más legible.
En el navegador tenemos como resultado:
Si solicitamos una página inexistente tenemos: