6. Distribución de frecuencias
La distribución de frecuencias es una tabla que organiza los datos en categorías o intervalos, mostrando cuántas veces aparece cada valor (o rango de valores). Es el primer paso para entender la estructura de una variable.
Los componentes clave de una tabla de frecuencias son:
Frecuencia Absoluta (f)
Es el número de veces que un valor específico aparece en el conjunto de datos. Es un simple conteo.
- Ejemplo: En el conjunto de edades
[25, 26, 25, 27, 25], la frecuencia absoluta de la edad 25 es 3. - La suma de todas las frecuencias absolutas es igual al número total de datos (N).
Frecuencia Relativa (fr)
Es la proporción de cada frecuencia absoluta respecto al total de datos. Pone el conteo en perspectiva.
- Fórmula:
fr = f / N, donde f es la frecuencia absoluta y N es el número total de datos. - Se puede expresar como una fracción, un decimal (entre 0 y 1) o un porcentaje (entre 0% y 100%).
- Ejemplo: En el conjunto anterior (N=5), la frecuencia relativa de la edad 25 es
3 / 5 = 0.6(o 60%). - La suma de todas las frecuencias relativas siempre es 1 (o 100%).
Frecuencia Acumulada
Suma las frecuencias de los valores a medida que se recorre la tabla (asumiendo que los datos están ordenados). Responde a la pregunta "¿cuántos datos son menores o iguales a este valor?".
- Frecuencia Absoluta Acumulada (F): Es la suma de las frecuencias absolutas de todos los valores menores o iguales al valor actual. El último valor de esta columna será igual a N.
- Frecuencia Relativa Acumulada (Fr): Es la suma de las frecuencias relativas. El último valor de esta columna siempre será 1 (o 100%).
Tabla de frecuencias con Pandas
import pandas as pd
edades = [21, 22, 21, 23, 25, 25, 25, 26, 27, 27, 27, 27, 30, 31, 31, 31]
serie = pd.Series(edades)
tabla = pd.DataFrame({
"Frecuencia absoluta": serie.value_counts().sort_index(),
"Frecuencia relativa": serie.value_counts(normalize=True).sort_index()
})
tabla["Frecuencia acumulada"] = tabla["Frecuencia absoluta"].cumsum()
tabla["Frecuencia relativa acumulada"] = tabla["Frecuencia relativa"].cumsum()
print(tabla)👉 Esto genera una tabla que muestra f, fr, F, Fr.
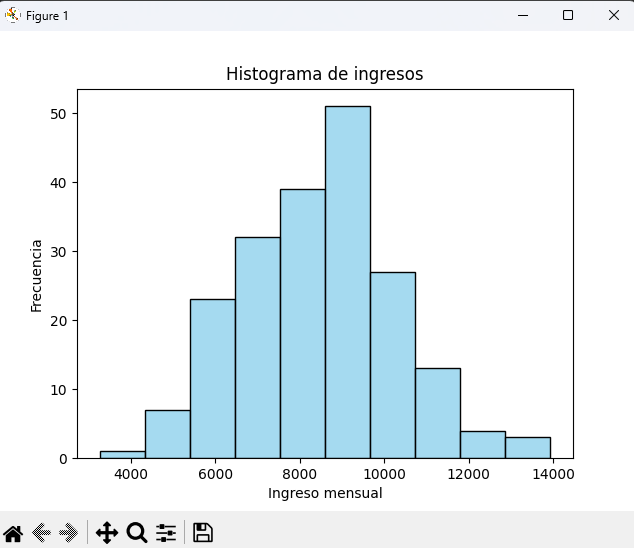
Histograma (variables numéricas continuas)
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(42)
ingresos = np.random.normal(8500, 2000, 200).round(0)
sns.histplot(ingresos, bins=10, kde=False, color="skyblue")
plt.title("Histograma de ingresos")
plt.xlabel("Ingreso mensual")
plt.ylabel("Frecuencia")
plt.show()👉 Los histogramas muestran intervalos (clases) y cuántos valores caen en cada uno.
Histograma con densidad (KDE)
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(42)
ingresos = np.random.normal(8500, 2000, 200).round(0)
sns.histplot(ingresos, bins=15, kde=True, color="orange")
plt.title("Histograma con curva de densidad")
plt.xlabel("Ingreso mensual")
plt.ylabel("Frecuencia")
plt.show()👉 La curva KDE suaviza la distribución, útil para ver la forma de los datos.
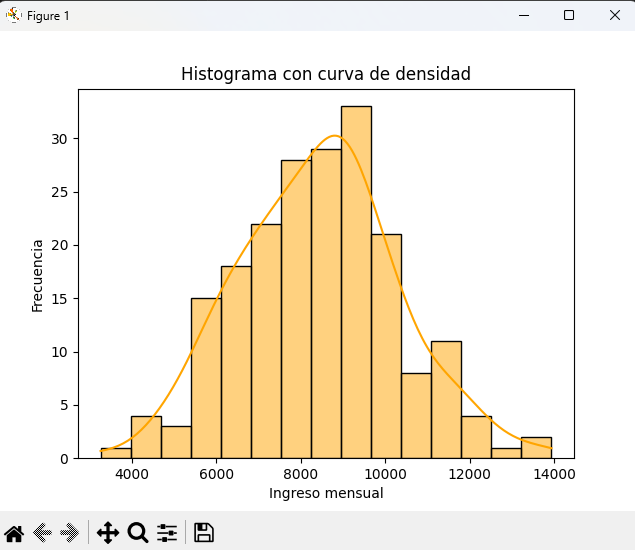
Diagrama de barras (variables categóricas)
import pandas as pd
import matplotlib.pyplot as plt
categorias = ["A", "B", "A", "C", "B", "B", "A", "C", "C", "C", "A", "B"]
serie = pd.Series(categorias)
conteo = serie.value_counts()
conteo.plot(kind="bar", color="lightcoral")
plt.title("Diagrama de barras - Categorías")
plt.xlabel("Categoría")
plt.ylabel("Frecuencia")
plt.show()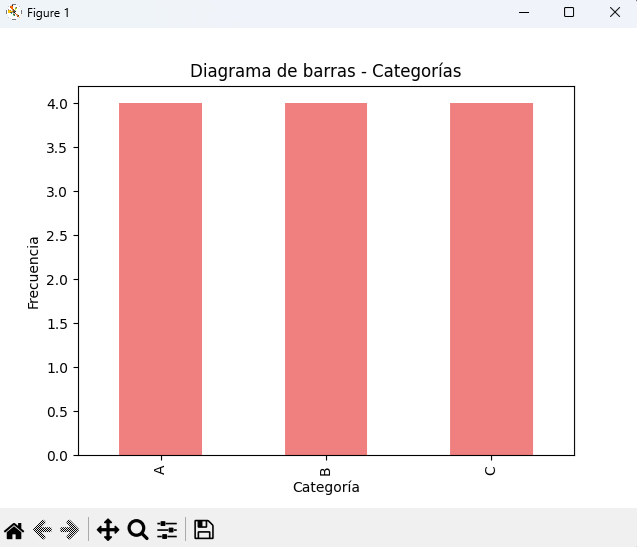
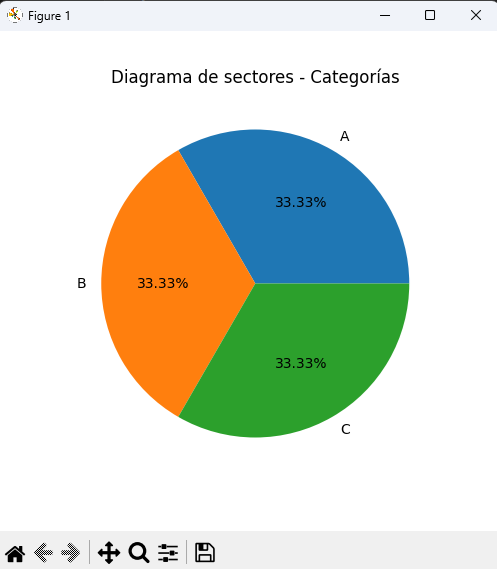
Diagrama de sectores (pie chart)
import pandas as pd
import matplotlib.pyplot as plt
categorias = ["A", "B", "A", "C", "B", "B", "A", "C", "C", "C", "A", "B"]
serie = pd.Series(categorias)
conteo = serie.value_counts()
conteo.plot(kind="pie", autopct="%.2f%%", figsize=(5, 5))
plt.title("Diagrama de sectores - Categorías")
plt.ylabel("") # ocultar etiqueta de eje Y
plt.show()👉 Los diagramas de sectores muestran proporciones, aunque no son tan precisos como los histogramas o barras.