Cuando trabajás con datos tabulares, Pandas y NumPy se integran de manera natural con Matplotlib. Podés graficar directamente desde DataFrames, preparar series temporales y realizar cálculos vectorizados con NumPy sin perder la API orientada a objetos de Matplotlib.
9.1 Graficar directamente DataFrames de Pandas
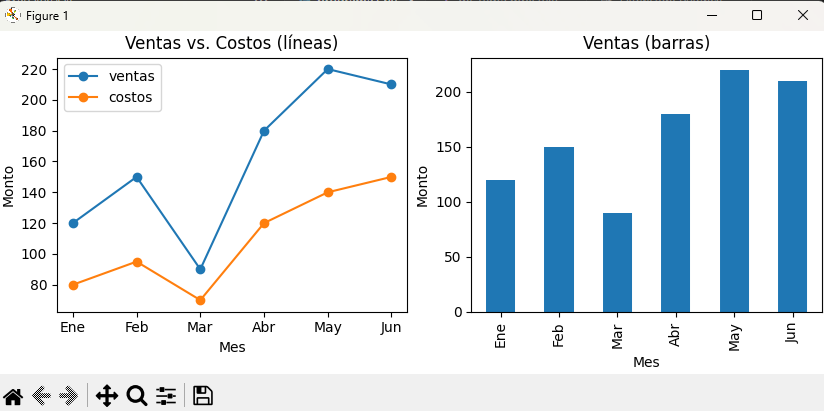
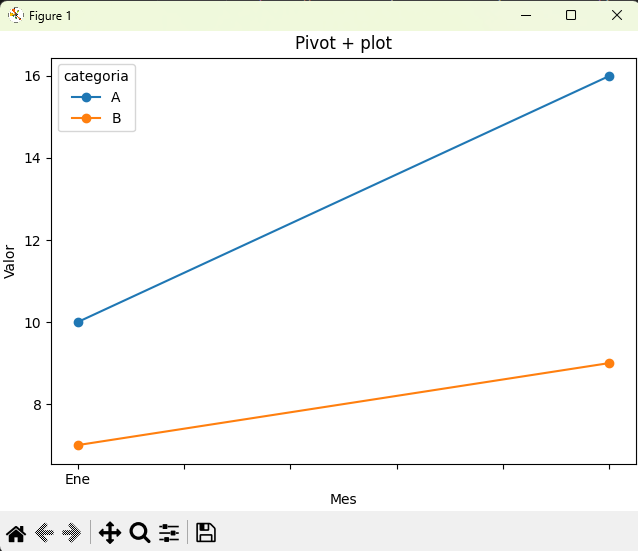
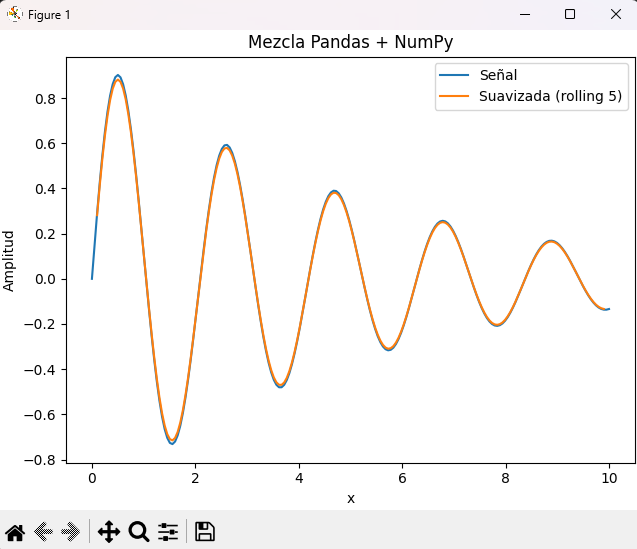
Pandas usa Matplotlib como backend de visualización. Es posible llamar a DataFrame.plot() o Series.plot() pasando un objeto Axes para mantener el control OO.
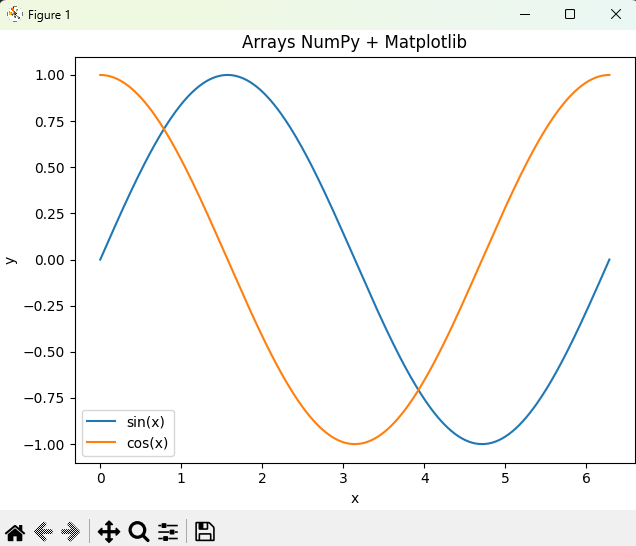
import numpy as np
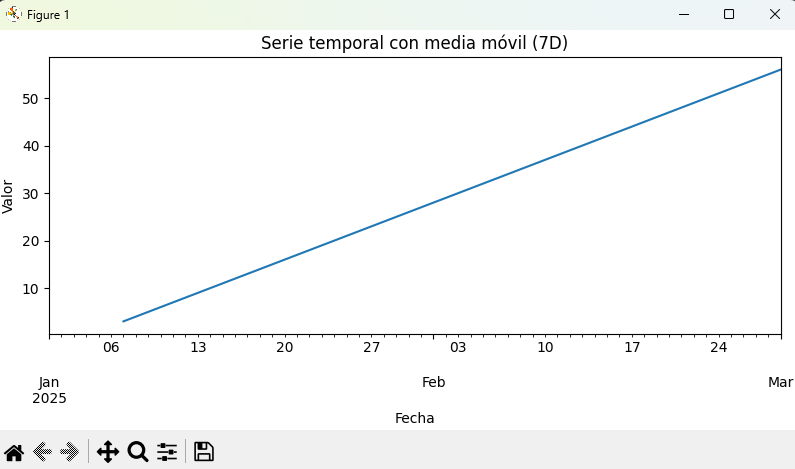
v = df["signal"].to_numpy()
df["abs_signal"] = np.abs(v)
9.3 Ejemplo práctico con Titanic
Cargamos el dataset Titanic desde Seaborn, lo convertimos en un DataFrame de Pandas y generamos gráficos con Matplotlib manteniendo la API orientada a objetos.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# 1) Cargar y preparar datos
Titanic = sns.load_dataset("titanic")
Titanic = Titanic[["survived", "class", "sex", "age", "fare"]].dropna()
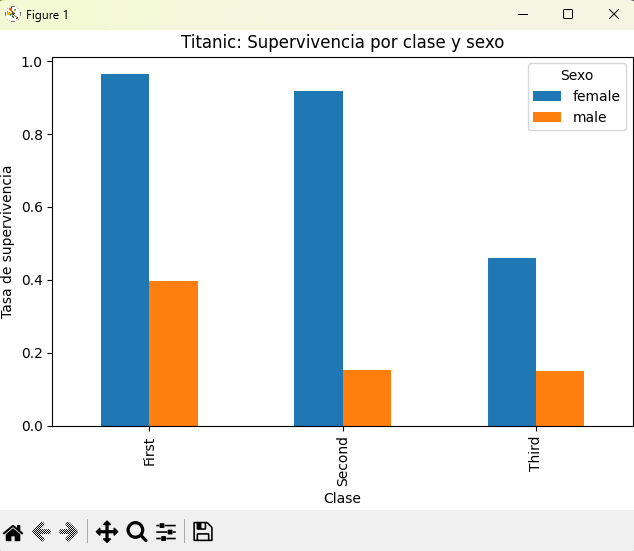
# 2) Tasa de supervivencia por clase y sexo
fig, ax = plt.subplots(layout="constrained")
survival_rate = Titanic.groupby(["class", "sex"])["survived"].mean().unstack()
survival_rate.plot(kind="bar", ax=ax)
ax.set_title("Titanic: Supervivencia por clase y sexo")
ax.set_xlabel("Clase")
ax.set_ylabel("Tasa de supervivencia")
ax.legend(title="Sexo")
plt.show()
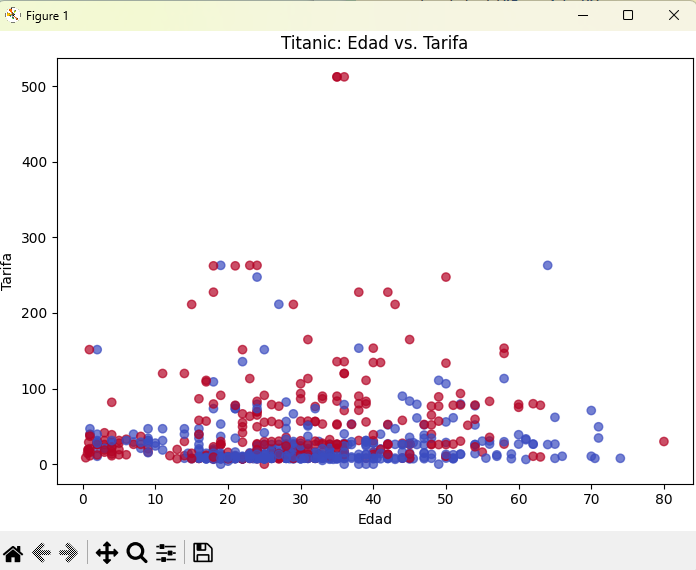
# 3) Dispersión: edad vs. tarifa (fare)
fig, ax = plt.subplots(figsize=(7, 5), layout="constrained")
ax.scatter(Titanic["age"], Titanic["fare"], c=Titanic["survived"], cmap="coolwarm", alpha=0.7)
ax.set_title("Titanic: Edad vs. Tarifa")
ax.set_xlabel("Edad")
ax.set_ylabel("Tarifa")
plt.show()
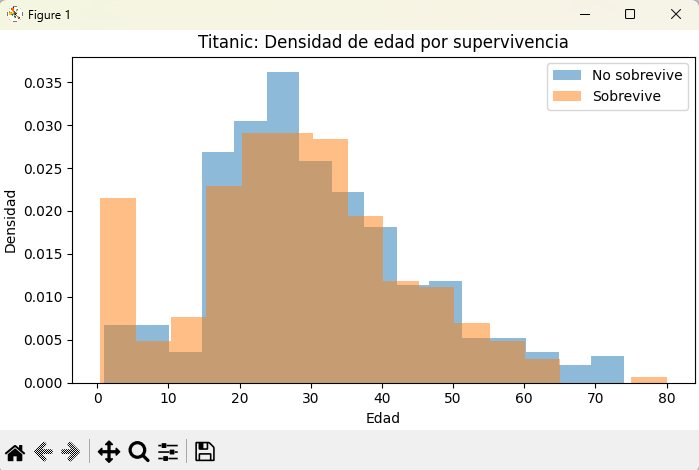
# 4) Histogramas de edad por supervivencia
fig, ax = plt.subplots(figsize=(7, 4), layout="constrained")
for survived, subset in Titanic.groupby("survived"):
etiqueta = "Sobrevive" if survived == 1 else "No sobrevive"
ax.hist(subset["age"], bins="auto", alpha=0.5, density=True, label=etiqueta)
ax.set_title("Titanic: Densidad de edad por supervivencia")
ax.set_xlabel("Edad")
ax.set_ylabel("Densidad")
ax.legend()
plt.show()
💡 El mismo flujo se puede adaptar a otros archivos CSV con pd.read_csv manteniendo la estructura de figuras y ejes.