1. Introducción a Pandas
Pandas es una librería de Python especializada en el manejo y análisis de datos. Su nombre proviene de Panel Data (datos en panel), un término de la econometría.
Lo que hace a Pandas tan popular es que ofrece estructuras de datos potentes y flexibles que permiten trabajar con información tabular (como hojas de cálculo o tablas de bases de datos) de manera sencilla y eficiente.
1.1 ¿Por qué es tan usado en Ciencia de Datos?
- 📊 Facilidad de uso: Permite cargar, limpiar y transformar datos con muy pocas líneas de código.
- ⚡ Rendimiento: Está construido sobre NumPy, lo que le da gran velocidad para operaciones numéricas.
- 🔄 Interoperabilidad: Se integra con muchas otras librerías como Matplotlib, Seaborn, Scikit-Learn y frameworks de bases de datos.
- 🛠 Versatilidad: Sirve para tareas de preprocesamiento, análisis estadístico, manipulación de datos y visualización.
En pocas palabras: Pandas es la herramienta estándar para manipulación de datos en Python, y es prácticamente imposible trabajar en Ciencia de Datos sin usarla.
1.2 Instalación y primeros pasos
Para comenzar a usar Pandas, lo instalamos desde pip, el gestor de paquetes de Python:
pip install pandas
💡 Consejo: muchas distribuciones para Ciencia de Datos como Anaconda ya traen Pandas instalado por defecto.
1.3 Primer programa con Pandas
Una vez instalado, se importa con la convención estándar:
import pandas as pd
# Crear una Serie (columna de datos)
serie = pd.Series([10, 20, 30, 40, 50])
print("Serie:")
print(serie)
# Crear un DataFrame (tabla)
datos = {
"Nombre": ["Ana", "Luis", "Carla", "Pedro"],
"Edad": [23, 35, 29, 42],
"Ciudad": ["Córdoba", "Buenos Aires", "Rosario", "Mendoza"]
}
df = pd.DataFrame(datos)
print("\nDataFrame:")
print(df)
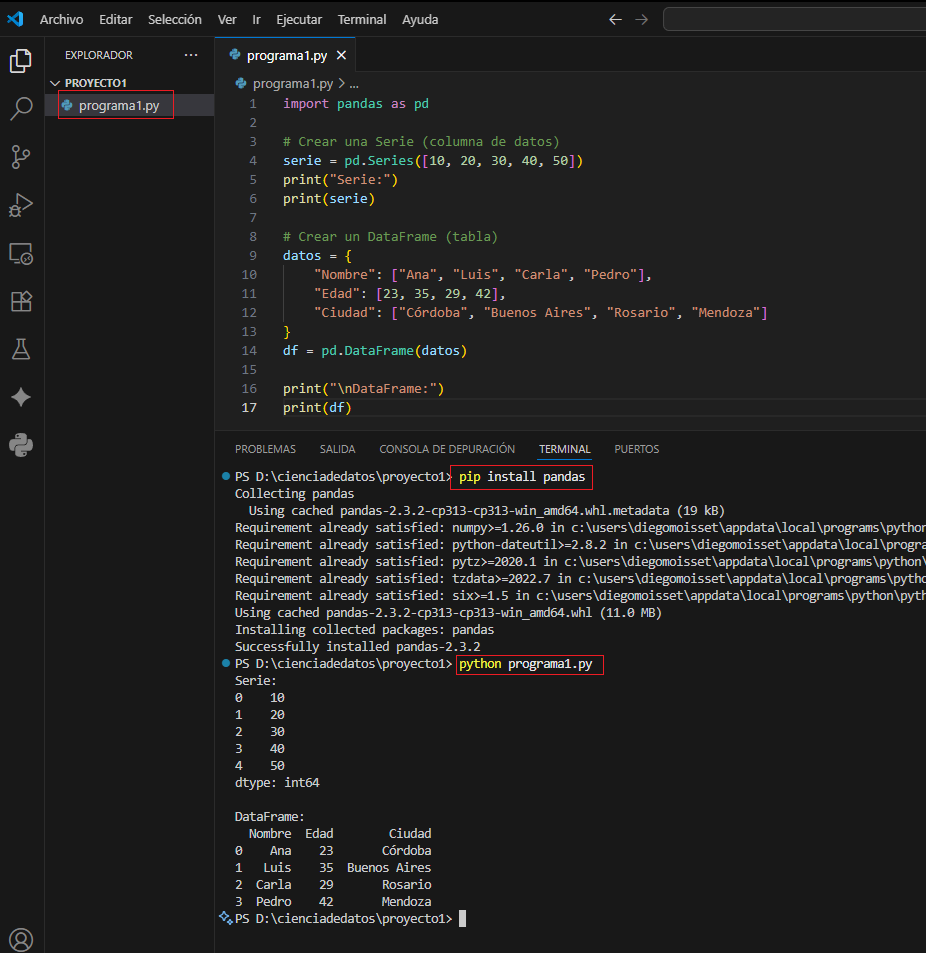
Salida esperada:
Serie:
0 10
1 20
2 30
3 40
4 50
dtype: int64
DataFrame:
Nombre Edad Ciudad
0 Ana 23 Córdoba
1 Luis 35 Buenos Aires
2 Carla 29 Rosario
3 Pedro 42 Mendoza
Vemos que Series son como columnas individuales y DataFrames son tablas completas. Estas dos estructuras son la base de todo lo que haremos con Pandas.
1.4 Diferencias con NumPy y cuándo usar cada uno
Aunque Pandas está construido sobre NumPy, existen diferencias importantes:
| Característica | NumPy | Pandas |
|---|---|---|
| Estructura principal | Arrays multidimensionales | Series (1D) y DataFrames (2D) |
| Tipo de datos | Homogéneos (todos del mismo tipo) | Heterogéneos (cada columna puede tener distinto tipo) |
| Indexación | Numérica (0, 1, 2, ...) | Etiquetas personalizadas (nombres de columnas, índices de filas) |
| Casos de uso | Cálculos matemáticos, álgebra lineal, simulaciones numéricas | Manejo de datos tabulares, limpieza, análisis y preprocesamiento |
| Facilidad de uso | Más técnico y matemático | Más cercano a hojas de cálculo o SQL |
¿Cuándo usar cada uno?
NumPy: cuando necesitás operaciones numéricas de bajo nivel, trabajar con vectores y matrices homogéneas, álgebra lineal, transformaciones rápidas y simulaciones matemáticas.
Pandas: cuando trabajás con datos tabulares (como hojas de Excel, CSV o bases de datos), necesitás manipular columnas con distintos tipos de datos (texto, fechas, números) y realizar análisis más cercanos a la práctica de la Ciencia de Datos.
Lo ideal es usar ambos de manera complementaria: NumPy para cálculos intensivos y Pandas para manipulación de datos.