3. Lectura y escritura de datos en Pandas
Una de las mayores ventajas de Pandas es la facilidad para importar y exportar datos en distintos formatos dentro de proyectos de Python. Con apenas unas pocas líneas de código podemos trabajar con CSV, Excel, JSON, archivos de texto plano e incluso conectarnos a bases de datos relacionales.
3.1 Archivos CSV, TSV y de texto plano
Los archivos CSV (Comma Separated Values) son el formato más extendido para intercambio de datos tabulares.
Leer un archivo CSV
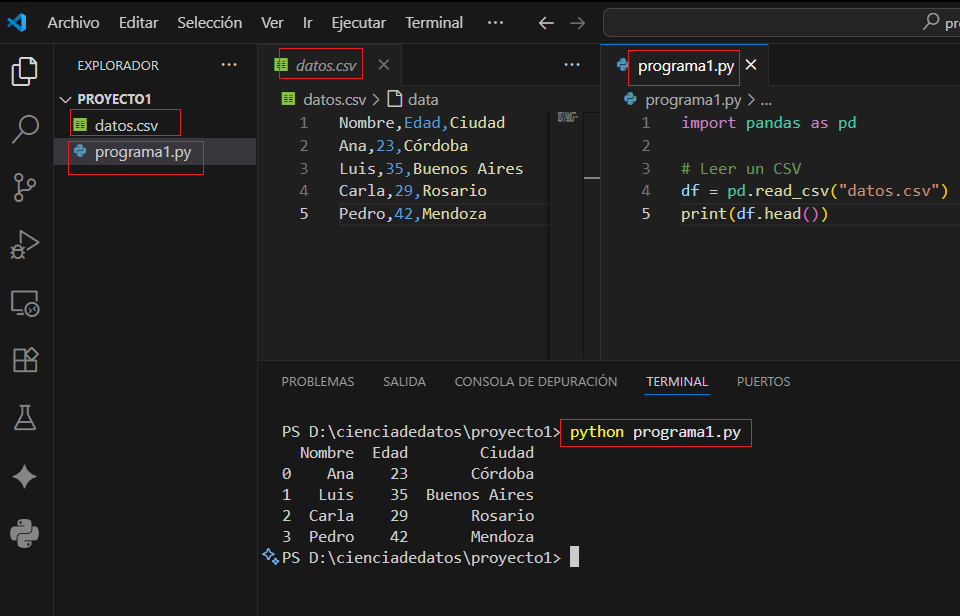
import pandas as pd
# Leer un CSV
df = pd.read_csv("datos.csv")
print(df.head())
Ejemplo de datos.csv:
Nombre,Edad,Ciudad
Ana,23,Córdoba
Luis,35,Buenos Aires
Carla,29,Rosario
Pedro,42,Mendoza
Salida:
Nombre Edad Ciudad
0 Ana 23 Córdoba
1 Luis 35 Buenos Aires
2 Carla 29 Rosario
3 Pedro 42 Mendoza
Leer un archivo TSV (Tab Separated Values)
Un archivo TSV (Valores Separados por Tabulaciones) es un archivo de texto plano que almacena datos tabulares donde cada fila representa un registro y los valores de cada columna están separados por caracteres de tabulación en lugar de comas.
df_tsv = pd.read_csv("datos.tsv", sep="\t")
print(df_tsv.head())
Leer archivos de texto plano
df_txt = pd.read_csv("datos.txt", sep=";")
print(df_txt.head())
Guardar un DataFrame en CSV
# Guardar en CSV
df.to_csv("salida.csv", index=False) # index=False evita guardar la columna de índices
👉 Con estas funciones podés intercambiar tablas con Excel, Google Sheets, bases de datos y otros programas de manera directa.
3.2 Archivos Excel
Pandas también puede trabajar con archivos Excel (.xlsx, .xls), aunque requiere instalar openpyxl o xlrd para manejar los formatos modernos.
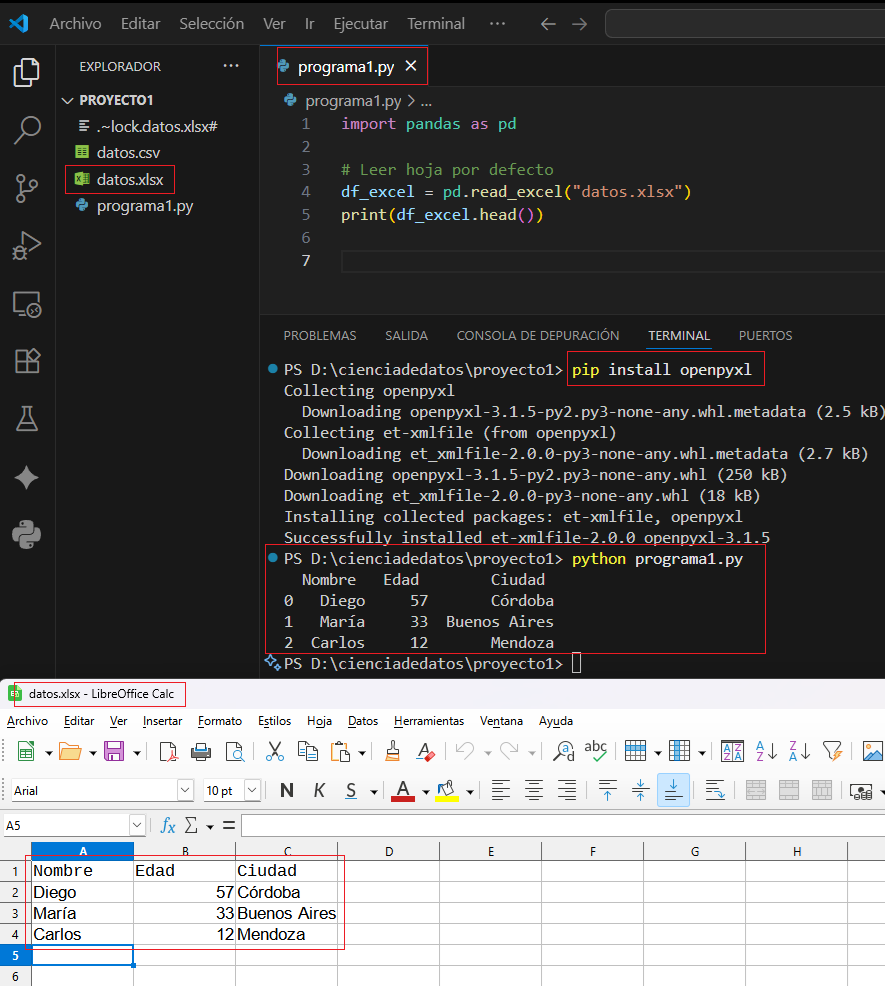
Instalar el motor recomendado
pip install openpyxl
Leer un archivo Excel
# Leer hoja por defecto
df_excel = pd.read_excel("datos.xlsx")
print(df_excel.head())
# Leer una hoja específica
df_hoja = pd.read_excel("datos.xlsx", sheet_name="Hoja1")
Guardar un DataFrame en Excel
df.to_excel("salida.xlsx", sheet_name="Resultados", index=False)
👉 Ideal para entornos empresariales o académicos donde Excel es el estándar y se requiere compatibilidad bidireccional.
3.3 Archivos JSON
El formato JSON (JavaScript Object Notation) es común en APIs y aplicaciones web. Si querés profundizar en este formato, revisá el tutorial de JSON Ya.
Ejemplo de datos.json:
[
{"Nombre": "Ana", "Edad": 23, "Ciudad": "Córdoba"},
{"Nombre": "Luis", "Edad": 35, "Ciudad": "Buenos Aires"},
{"Nombre": "Carla", "Edad": 29, "Ciudad": "Rosario"}
]
Leer JSON con Pandas
df_json = pd.read_json("datos.json")
print(df_json)
Salida:
Nombre Edad Ciudad
0 Ana 23 Córdoba
1 Luis 35 Buenos Aires
2 Carla 29 Rosario
Guardar un DataFrame en JSON
df.to_json("salida.json", orient="records", indent=4)
👉 El parámetro orient define la estructura de salida: "records" (lista de diccionarios), "split", "index", entre otros.
3.4 Conexión a bases de datos
Pandas permite leer y escribir directamente desde bases de datos relacionales como MySQL, PostgreSQL o SQLite, generalmente en conjunto con SQLAlchemy.
Ejemplo con SQLite
import sqlite3
import pandas as pd
# Conexión a base SQLite
conexion = sqlite3.connect("mibase.db")
# Crear un DataFrame con algunos datos de prueba
data = {
"nombre": ["Juan", "María", "Pedro", "Ana"],
"edad": [25, 30, 35, 28],
"ciudad": ["Madrid", "Barcelona", "Sevilla", "Valencia"]
}
df = pd.DataFrame(data)
# Guardar un DataFrame en la base de datos
df.to_sql("personas", conexion, if_exists="replace", index=False)
print("\nDataFrame guardado en la base de datos 'mibase.db' en la tabla 'personas'.")
# Leer los datos de la base de datos y guardarlos en otro DataFrame
df_leido = pd.read_sql("SELECT * FROM personas", conexion)
print("\nDataFrame leído de la base de datos:")
print(df_leido)
# Cerrar la conexión
conexion.close()
print("\nConexión a la base de datos cerrada.")
👉 Esta capacidad es fundamental en proyectos corporativos donde los datos viven en bases de datos y no en archivos sueltos.
Si deseás conocer más sobre bases de datos ligeras, explorá el tutorial de SQLite Ya.
3.5 Conexión a una base de datos MySQL
Además de SQLite, Pandas puede conectarse a bases de datos más robustas como MySQL o PostgreSQL. Para esto se utiliza la librería SQLAlchemy como intermediario entre Pandas y el motor de base de datos.
Instalación de dependencias
Necesitamos instalar:
pip install sqlalchemy pymysql
- SQLAlchemy: biblioteca para trabajar con SQL en Python.
- PyMySQL: conector específico para MySQL.
Conexión a MySQL y lectura de datos
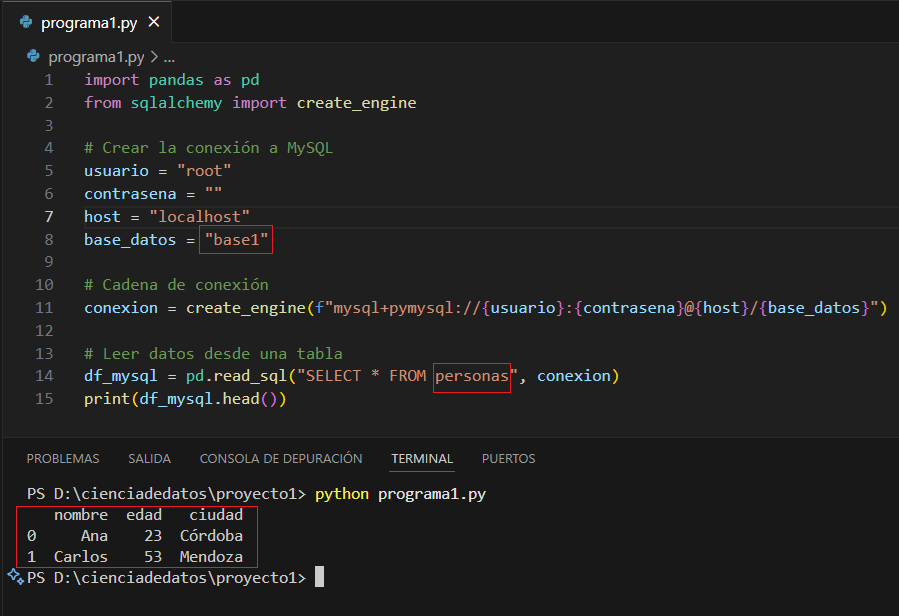
import pandas as pd
from sqlalchemy import create_engine
# Crear la conexión a MySQL
usuario = "root"
contrasena = "mi_password"
host = "localhost"
base_datos = "mi_base"
# Cadena de conexión
conexion = create_engine(f"mysql+pymysql://{usuario}:{contrasena}@{host}/{base_datos}")
# Leer datos desde una tabla
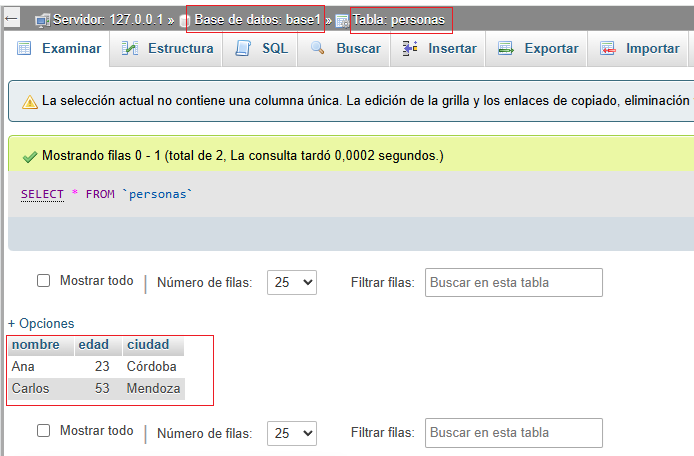
df_mysql = pd.read_sql("SELECT * FROM usuarios", conexion)
print(df_mysql.head())
👉 Esto trae los datos de la tabla usuarios a un DataFrame de Pandas, listo para analizar.
Guardar un DataFrame en MySQL
# Guardar un DataFrame en una tabla MySQL
df.to_sql("nueva_tabla", conexion, if_exists="replace", index=False)
Parámetros importantes:
if_exists="replace": reemplaza la tabla si ya existe.if_exists="append": agrega los datos al final de la tabla existente.
Diferencias con SQLite
- SQLite se guarda en un archivo (
.db), mientras que MySQL requiere un servidor activo. - MySQL permite múltiples usuarios, mayor escalabilidad y soporte para proyectos grandes.
- Con Pandas, la forma de trabajar es casi idéntica: solo cambia la cadena de conexión.
📌 Con esto, ya tenés una conexión profesional y escalable entre Pandas y MySQL, lista para proyectos reales de ciencia de datos.
Si querés profundizar en bases de datos relacionales, te recomendamos el tutorial de MySQL Ya.
Resumen
- CSV/TSV/TXT: formatos rápidos y livianos para compartir datos tabulares.
- Excel: indispensable en empresas y entornos educativos.
- JSON: ideal para APIs y aplicaciones web.
- Bases de datos: conexión directa para proyectos profesionales.
Con estas herramientas, Pandas se convierte en un puente universal para leer y guardar datos en cualquier formato.