23. Guías de solución de problemas e incidentes comunes
23.1 Introducción
Las guías de solución de problemas ayudan a diagnosticar y resolver fallas frecuentes en un sistema de software. Son documentos prácticos que se consultan cuando algo no funciona como se espera: un usuario no puede ingresar, una operación falla, un servicio no responde, una integración se interrumpe o un proceso queda pendiente.
Estas guías son especialmente importantes para soporte, operación y mantenimiento. Permiten actuar con rapidez, reducir consultas repetidas, escalar con mejor información y registrar aprendizajes después de incidentes.
En este tema veremos cómo documentar síntomas, causas probables, pasos de diagnóstico, acciones correctivas, criterios de escalamiento, severidad, comunicación y aprendizaje posterior.
23.2 Qué es una guía de solución de problemas
Una guía de solución de problemas, también llamada guía de troubleshooting, es un documento que orienta el análisis de una falla. No solo indica una solución, sino que ayuda a identificar la causa probable a partir de síntomas observables.
A diferencia de una guía de operación general, esta documentación se enfoca en situaciones anómalas. Debe ser concreta, rápida de consultar y orientada a acción. Quien la usa puede estar bajo presión, por lo que necesita instrucciones claras.
23.3 Elementos de una guía de incidentes
La imagen muestra los elementos de una guía de solución de problemas: síntoma, impacto, causas probables, diagnóstico, acciones correctivas, verificación, escalamiento, comunicación y registro posterior del incidente.
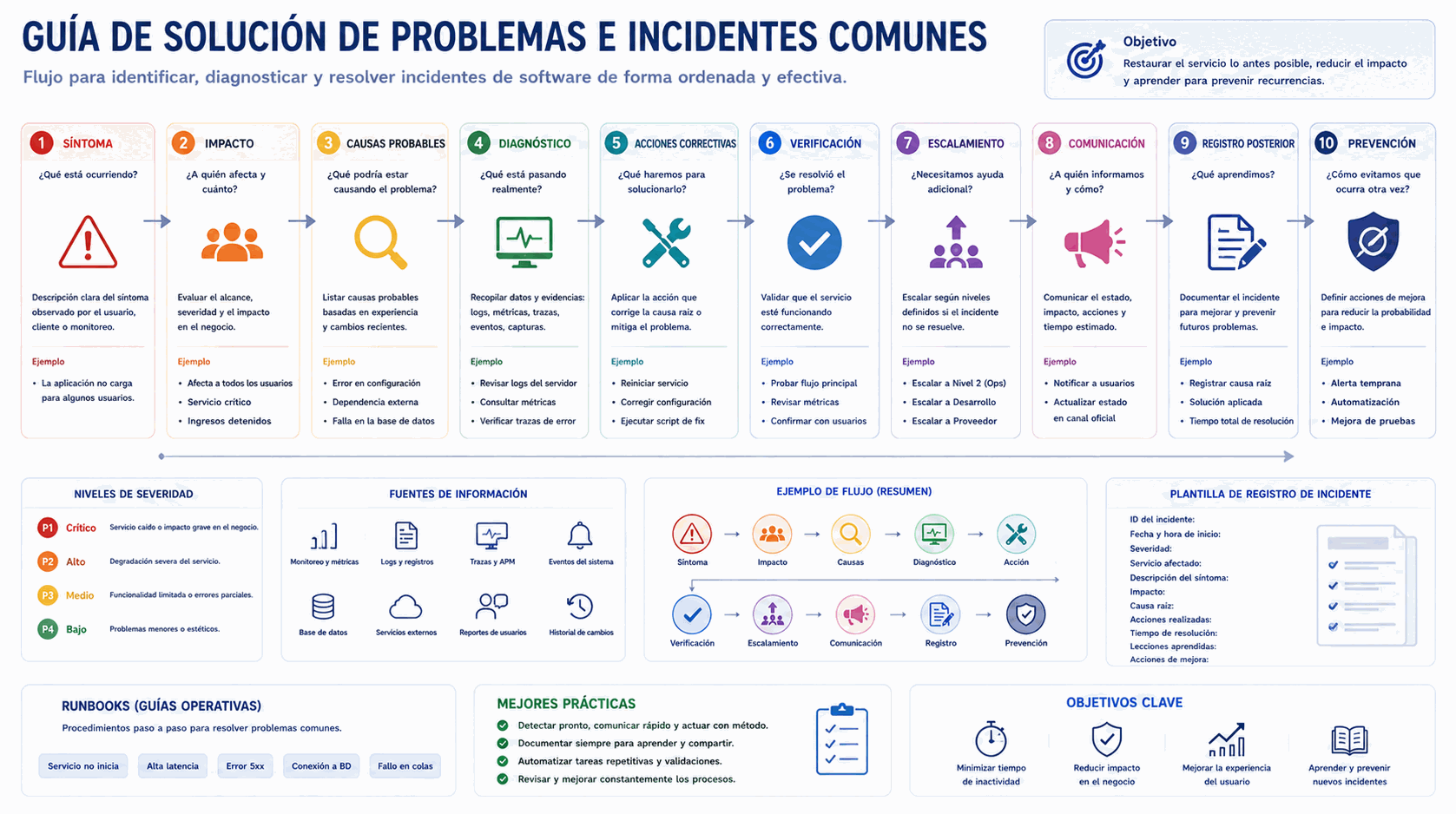
23.4 Síntomas
El síntoma es lo que se observa: un mensaje de error, una demora, una pantalla vacía, una operación rechazada, un servicio caído o una alerta. Documentar síntomas ayuda a que soporte y operación puedan comenzar el diagnóstico sin conocer todavía la causa.
Un síntoma debe describirse con precisión. "El sistema no funciona" es demasiado general. Es mejor indicar: "El usuario recibe el mensaje 'sesión vencida' al intentar reservar un turno" o "El endpoint de salud responde con código 500".
23.5 Impacto
El impacto indica a quién afecta el problema y con qué gravedad. Puede afectar a un usuario, un grupo, una funcionalidad, un servicio interno o todo el sistema. Documentar impacto ayuda a priorizar y decidir si se requiere escalamiento urgente.
No todos los incidentes tienen la misma severidad. Un error visual menor no equivale a una caída total del sistema. La guía debe ayudar a distinguir impacto funcional, operativo y de negocio.
23.6 Causas probables
Una guía útil enumera causas probables asociadas a cada síntoma. Por ejemplo, un error de inicio de sesión puede deberse a credenciales incorrectas, cuenta bloqueada, servicio de autenticación caído, token vencido o problema de configuración.
Las causas probables no deben presentarse como certezas. Deben guiar verificaciones. El objetivo es evitar diagnósticos apresurados y recorrer un camino razonable desde lo más común hacia lo más complejo.
23.7 Pasos de diagnóstico
Los pasos de diagnóstico indican qué revisar para confirmar o descartar causas. Pueden incluir consultar registros, revisar métricas, probar un endpoint, verificar configuración, comprobar conectividad, revisar estado de colas o confirmar permisos del usuario.
Los pasos deben estar ordenados. Conviene empezar por verificaciones rápidas y de bajo riesgo. También debe indicarse qué resultado esperar y qué hacer según cada resultado.
23.8 Acciones correctivas
Las acciones correctivas son tareas que pueden resolver o mitigar el problema: reiniciar un servicio, liberar una cola, corregir una configuración, reintentar un proceso, desbloquear una cuenta, restaurar datos o activar un procedimiento de contingencia.
Cada acción debe indicar riesgos y condiciones. Reiniciar un servicio puede afectar usuarios. Reprocesar mensajes puede duplicar operaciones si no existe control. Restaurar datos puede perder cambios recientes. La documentación debe advertir estas consecuencias.
23.9 Verificación de recuperación
Después de aplicar una acción, es necesario verificar si el sistema se recuperó. La guía debe indicar cómo confirmar la recuperación: revisar métricas, repetir la operación, consultar registros, validar una cola vacía o pedir confirmación a soporte.
Sin verificación, el equipo puede creer que resolvió el problema cuando solo ocultó un síntoma temporalmente.
23.10 Escalamiento
Una guía debe indicar cuándo escalar el problema y a quién. El escalamiento puede ir a desarrollo, operación, seguridad, base de datos, proveedor externo o responsable de producto.
También debe indicar qué información enviar: hora del incidente, usuario afectado, identificador de operación, mensaje de error, registros relevantes, pasos ya realizados y resultado de diagnósticos. Esto evita perder tiempo repitiendo preguntas.
23.11 Comunicación
Algunos incidentes requieren comunicación a usuarios, soporte, gestión o equipos internos. La documentación puede incluir criterios para comunicar, canales, mensajes base y frecuencia de actualización.
La comunicación debe ser clara y cuidadosa. Debe indicar impacto, estado, acciones en curso y próximos pasos, sin prometer una solución antes de tener información suficiente.
23.12 Tabla de troubleshooting
| Síntoma | Causa probable | Diagnóstico | Acción |
|---|---|---|---|
| Usuario no puede iniciar sesión. | Cuenta bloqueada o credenciales inválidas. | Revisar estado de cuenta y registro de autenticación. | Restablecer acceso o escalar a seguridad. |
| Reserva de turno falla. | Horario ocupado o validación de disponibilidad. | Consultar estado del turno y registros del servicio. | Indicar nuevo horario o escalar si hay inconsistencia. |
| Notificaciones no llegan. | Cola detenida o proveedor externo fallando. | Revisar cola, consumidores y estado del proveedor. | Reiniciar consumidor o activar contingencia. |
23.13 Severidad
La severidad clasifica la gravedad de un incidente. Puede depender de cantidad de usuarios afectados, funcionalidad impactada, pérdida de datos, impacto económico, seguridad o disponibilidad.
Documentar severidades ayuda a priorizar y coordinar respuesta. Por ejemplo, una caída total de producción puede ser severidad alta, mientras que un error en una pantalla secundaria puede ser menor.
23.14 Registro posterior del incidente
Después de resolver un incidente, conviene registrar qué ocurrió, causa raíz, impacto, línea de tiempo, acciones tomadas y mejoras pendientes. Esto evita repetir el mismo problema y ayuda a mejorar monitoreo, pruebas y documentación.
Si la guía de solución de problemas fue insuficiente, debe actualizarse. Cada incidente real es una oportunidad para mejorar documentación operativa.
23.15 Relación con soporte y operación
Las guías de solución de problemas conectan soporte y operación. Soporte detecta síntomas desde usuarios. Operación observa métricas y servicios. Desarrollo puede investigar causas técnicas. Una guía común ayuda a coordinar estos roles.
También permite separar problemas que soporte puede resolver directamente de aquellos que requieren intervención técnica más profunda.
23.16 Errores frecuentes
Al crear guías de solución de problemas suelen aparecer estos errores:
- Describir soluciones sin explicar síntomas ni diagnóstico.
- No indicar impacto o severidad.
- Proponer acciones riesgosas sin advertencias.
- No indicar cómo verificar recuperación.
- No definir criterios de escalamiento.
- Usar lenguaje técnico excesivo para soporte de primer nivel.
- No actualizar la guía después de incidentes reales.
23.17 Qué debes recordar de este tema
- Una guía de solución de problemas parte de síntomas observables.
- Debe incluir causas probables, diagnóstico, acciones y verificación.
- El impacto y la severidad ayudan a priorizar respuesta.
- Las acciones correctivas deben indicar riesgos y condiciones.
- El escalamiento necesita criterios claros e información mínima.
- Los incidentes resueltos deben alimentar mejoras en la documentación.
- Una guía útil permite actuar bajo presión con menos improvisación.
23.18 Conclusión
Las guías de solución de problemas convierten experiencia operativa en conocimiento reutilizable. Ayudan a diagnosticar, corregir, escalar y aprender de incidentes comunes.
En el próximo tema estudiaremos la documentación de seguridad: permisos, amenazas, controles y datos sensibles.