1. ¿Qué es el Deep Learning?
1.1 Introducción
El Deep Learning, o aprendizaje profundo, es una rama del Machine Learning que utiliza redes neuronales artificiales con muchas capas para aprender patrones complejos a partir de los datos. La palabra deep significa "profundo" porque estos modelos no tienen una sola capa de procesamiento, sino varias capas intermedias que transforman la información paso a paso.
Dicho de forma simple: en lugar de programar una computadora con reglas exactas para resolver un problema, se le muestran muchos ejemplos y el sistema aprende por sí mismo qué patrones son importantes. Por ejemplo, si queremos que una máquina reconozca perros en imágenes, no escribimos reglas como "si tiene cuatro patas y dos orejas". En cambio, mostramos miles de imágenes etiquetadas y la red neuronal aprende qué rasgos visuales distinguen a un perro.
El Deep Learning ha sido uno de los motores principales del avance reciente de la inteligencia artificial porque permite resolver problemas que antes eran muy difíciles para las computadoras, como reconocer rostros, entender voz humana, traducir textos, detectar enfermedades en imágenes médicas o generar contenido nuevo.
1.2 Una definición intuitiva
Podemos pensar el Deep Learning como un sistema de aprendizaje en capas:
- La primera capa recibe los datos de entrada, por ejemplo los píxeles de una imagen.
- Las capas intermedias van detectando patrones cada vez más complejos.
- La última capa produce una salida, como una clasificación o una predicción.
Si tomamos el caso de una imagen de un gato, las primeras capas podrían detectar bordes y colores. Las siguientes podrían reconocer formas como ojos, orejas o bigotes. Finalmente, la última capa combinaría toda esa información para decidir si la imagen corresponde o no a un gato.
1.3 ¿Por qué se llama red neuronal?
Se llama red neuronal porque está inspirada, de manera muy simplificada, en el funcionamiento del cerebro humano. Nuestro cerebro está formado por neuronas conectadas entre sí. Cada neurona recibe señales, las procesa y transmite una respuesta a otras neuronas.
En una red neuronal artificial ocurre algo parecido:
- Cada neurona artificial recibe valores de entrada.
- A cada entrada se le asigna una importancia, llamada peso.
- La neurona combina esas entradas y decide cuánto activar su salida.
- La salida pasa a otras neuronas de la siguiente capa.
Es importante aclarar que una red neuronal artificial no funciona igual que el cerebro humano. Solo toma de él la idea general de unidades conectadas que procesan información de manera distribuida.
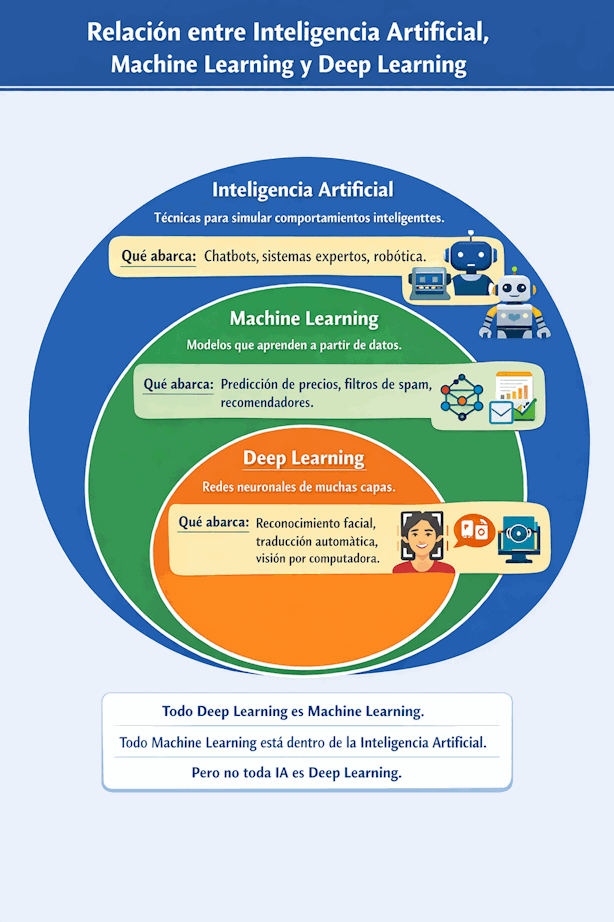
1.4 Relación entre IA, Machine Learning y Deep Learning
Estos términos suelen confundirse, pero no significan lo mismo. La relación correcta es jerárquica:
- Inteligencia Artificial: campo general que busca crear sistemas capaces de realizar tareas que requieren inteligencia humana.
- Machine Learning: subárea de la IA en la que las máquinas aprenden a partir de datos.
- Deep Learning: subárea del Machine Learning basada en redes neuronales profundas.
| Concepto | Qué abarca | Ejemplos |
|---|---|---|
| Inteligencia Artificial | Técnicas para simular comportamientos inteligentes. | Chatbots, sistemas expertos, robótica. |
| Machine Learning | Modelos que aprenden a partir de datos. | Predicción de precios, filtros de spam, recomendadores. |
| Deep Learning | Machine Learning con redes neuronales de muchas capas. | Reconocimiento facial, traducción automática, visión por computadora. |
En resumen: todo Deep Learning es Machine Learning, y todo Machine Learning pertenece al campo de la Inteligencia Artificial, pero no toda IA es Deep Learning.
1.5 ¿Qué problema vino a resolver?
Antes del auge del Deep Learning, muchos sistemas dependían de que un experto definiera manualmente las características relevantes de los datos. Por ejemplo, para reconocer números escritos a mano, un programador podía intentar definir reglas sobre bordes, formas o proporciones.
Ese enfoque funcionaba en problemas simples, pero se volvía insuficiente cuando los datos eran muy complejos. Las imágenes, el audio y el lenguaje humano contienen muchísima variabilidad. Un mismo objeto puede verse distinto según la luz, el ángulo o el fondo. Una misma palabra puede sonar diferente según la persona que la pronuncie.
El Deep Learning permitió un cambio fundamental: el sistema aprende automáticamente qué características son útiles. Ya no hace falta diseñar a mano todos los atributos de entrada. La red neuronal descubre por sí misma qué patrones necesita detectar para resolver la tarea.
1.6 ¿Cómo aprende un modelo de Deep Learning?
El aprendizaje en Deep Learning ocurre mediante un proceso iterativo. Aunque más adelante veremos esto con detalle, aquí conviene tener una visión general:
- Se le entrega al modelo un conjunto de datos de entrada.
- El modelo produce una salida inicial, que al principio suele ser mala o poco precisa.
- Se compara esa salida con la respuesta correcta.
- Se calcula el error cometido.
- El sistema ajusta sus pesos internos para reducir ese error.
- El proceso se repite muchas veces hasta mejorar el rendimiento.
Imagina que una red neuronal intenta predecir si una foto contiene un perro o un gato. Al comienzo sus respuestas serán casi aleatorias. Pero después de ver miles de ejemplos y corregir sus errores, va afinando sus conexiones internas hasta aprender patrones más útiles.
1.7 ¿Qué significa que una red sea profunda?
Una red neuronal simple puede tener solo una capa oculta. En cambio, una red profunda tiene múltiples capas ocultas. Cada una aprende representaciones diferentes de los datos.
La profundidad importa porque permite construir conocimiento de forma gradual:
- Capas iniciales: detectan patrones simples.
- Capas intermedias: combinan esos patrones en estructuras más complejas.
- Capas finales: utilizan esa información para decidir o predecir.
Por ejemplo, en visión artificial:
- Primero se detectan líneas y bordes.
- Luego se reconocen texturas y formas.
- Después partes de objetos, como ruedas, ojos o manos.
- Finalmente se identifica el objeto completo.
Esta capacidad de construir representaciones jerárquicas es una de las razones por las que el Deep Learning es tan potente.
1.8 Ejemplo cotidiano para entenderlo mejor
Supongamos que queremos enseñar a un niño a reconocer frutas. No le damos una fórmula matemática, sino muchos ejemplos: manzanas rojas, verdes, grandes, pequeñas; bananas maduras e inmaduras; naranjas con diferentes tonalidades. Con el tiempo, el niño construye una idea mental de cada fruta.
Una red neuronal aprende de forma parecida. Al ver una gran cantidad de ejemplos, va ajustando internamente qué rasgos son relevantes. No aprende como un humano, pero sí aprende a partir de la experiencia representada por los datos.
La diferencia es que para lograr un buen rendimiento, las redes profundas suelen necesitar:
- Muchos datos.
- Capacidad de cómputo elevada.
- Un proceso de entrenamiento bien diseñado.
1.9 Diferencias entre programación tradicional y Deep Learning
En la programación tradicional, el programador define reglas exactas y la computadora las ejecuta. En Deep Learning, en cambio, el programador define la estructura del modelo y el proceso de entrenamiento, pero las reglas internas se aprenden a partir de los datos.
| Aspecto | Programación tradicional | Deep Learning |
|---|---|---|
| Reglas | Se escriben manualmente. | Se aprenden automáticamente a partir de datos. |
| Entrada | Datos + reglas. | Datos + respuestas esperadas durante el entrenamiento. |
| Salida | Resultado directo según las reglas. | Modelo entrenado capaz de generalizar. |
| Uso ideal | Problemas con lógica clara y precisa. | Problemas complejos con patrones difíciles de programar. |
Por eso el Deep Learning es tan útil en tareas donde el criterio de decisión es complicado de expresar con reglas fijas.
1.10 Principales aplicaciones del Deep Learning
El Deep Learning se utiliza en una enorme variedad de áreas. Algunos ejemplos importantes son:
- Visión por computadora: clasificación de imágenes, detección de objetos, reconocimiento facial, análisis médico por imágenes.
- Procesamiento del lenguaje natural: traductores automáticos, chatbots, análisis de sentimientos, generación de texto.
- Reconocimiento de voz: asistentes virtuales, transcripción automática, sistemas de comando por voz.
- Sistemas de recomendación: sugerencias en plataformas de video, música o comercio electrónico.
- Vehículos autónomos: interpretación del entorno a partir de cámaras y sensores.
- Finanzas: detección de fraude, análisis de riesgo, predicción de comportamientos.
- Industria: mantenimiento predictivo, control de calidad con imágenes, automatización inteligente.
En todos estos casos hay algo en común: los datos son complejos, abundantes y contienen patrones que no resultan sencillos de capturar con reglas escritas manualmente.
1.11 ¿Por qué tuvo tanto éxito en los últimos años?
El Deep Learning existe desde hace varias décadas, pero su gran crecimiento se produjo recientemente. Esto ocurrió principalmente por la combinación de tres factores:
- Más datos disponibles: internet, sensores, redes sociales, dispositivos móviles y sistemas digitales generaron enormes volúmenes de información.
- Más potencia de cálculo: el uso de GPU permitió entrenar redes neuronales mucho más rápido.
- Mejores algoritmos y herramientas: se desarrollaron técnicas más efectivas de entrenamiento y bibliotecas como PyTorch facilitaron la implementación.
Cuando estos tres elementos se combinaron, el Deep Learning empezó a superar claramente a otros métodos en muchas tareas complejas.
1.12 Ventajas del Deep Learning
- Aprende características automáticamente: reduce la necesidad de diseñar variables manualmente.
- Excelente rendimiento en datos complejos: especialmente en imágenes, audio y texto.
- Escala bien con grandes volúmenes de datos: cuanto más aprende, mejores resultados puede lograr.
- Gran flexibilidad: se puede adaptar a clasificación, regresión, generación de contenido y muchas otras tareas.
- Resultados de alto nivel: en algunos problemas ha alcanzado o superado rendimiento humano específico.
1.13 Limitaciones y desafíos
Aunque es muy poderoso, el Deep Learning no es mágico ni resuelve todo. También presenta limitaciones importantes:
- Necesita muchos datos: si el conjunto de entrenamiento es pequeño, el modelo puede no aprender bien.
- Requiere mucha computación: entrenar modelos grandes puede demandar tiempo y hardware costoso.
- Puede ser difícil de interpretar: muchas veces no es fácil entender por qué una red tomó cierta decisión.
- Puede sobreajustarse: a veces aprende demasiado bien los datos de entrenamiento pero falla con datos nuevos.
- Depende de la calidad de los datos: si los datos tienen errores o sesgos, el modelo aprenderá esos problemas.
Por eso un buen proyecto de Deep Learning no depende solo del modelo. También depende de tener datos adecuados, objetivos bien definidos y una evaluación rigurosa.
1.14 Un ejemplo conceptual paso a paso
Imaginemos que queremos construir un sistema que determine si una imagen contiene un número 0 o un número 1.
- Reunimos muchas imágenes etiquetadas de ceros y unos.
- Convertimos cada imagen en datos numéricos, por ejemplo píxeles.
- La red neuronal recibe esos valores como entrada.
- Las capas internas procesan la información.
- La salida final genera una probabilidad para cada clase.
- Se compara la predicción con la etiqueta correcta.
- Se corrigen los pesos de la red para reducir el error.
- Tras muchas repeticiones, el sistema aprende a distinguir ambos números.
Esto mismo, con mayor complejidad, se aplica luego a rostros, voz, documentos, radiografías, señales financieras o secuencias de texto.
1.15 ¿Qué papel juega PyTorch en todo esto?
PyTorch es una biblioteca de Python diseñada para trabajar con tensores y construir modelos de Deep Learning de manera flexible y eficiente. En este curso la utilizaremos porque permite:
- Definir redes neuronales de manera clara.
- Entrenar modelos con CPU o GPU.
- Calcular gradientes automáticamente.
- Experimentar con facilidad en proyectos educativos y profesionales.
En otras palabras, PyTorch es una herramienta que facilita la implementación práctica de todas las ideas teóricas que iremos estudiando.
1.16 Qué debes recordar de este tema
- El Deep Learning es una subárea del Machine Learning basada en redes neuronales profundas.
- Su fortaleza principal está en aprender patrones complejos directamente desde los datos.
- Es especialmente útil en imágenes, audio, texto y otros datos no estructurados.
- Aprende ajustando pesos internos para reducir el error en sus predicciones.
- Su éxito reciente se debe a más datos, mejor hardware y mejores herramientas.
- PyTorch será la biblioteca que utilizaremos para llevar estos conceptos a la práctica.
1.17 Conclusión
El Deep Learning representa una de las ideas más influyentes de la inteligencia artificial moderna. Su capacidad para aprender automáticamente representaciones complejas de los datos lo ha convertido en una tecnología central en numerosos campos.
Para un estudiante que comienza, lo más importante no es memorizar definiciones, sino comprender la idea principal: una red neuronal profunda aprende a transformar datos de entrada en respuestas útiles mediante múltiples capas de procesamiento y un proceso de entrenamiento basado en ejemplos.
En los próximos temas iremos construyendo este conocimiento paso a paso. Primero veremos cómo surgieron estas ideas y cómo evolucionaron las redes neuronales. Después profundizaremos en los conceptos fundamentales que hacen posible el entrenamiento de estos modelos en PyTorch.