10. Descenso del gradiente (Gradient Descent)
10.1 Introducción
En el tema anterior vimos que la función de pérdida nos dice qué tan equivocada está una red neuronal. Pero todavía falta responder una pregunta fundamental: ¿cómo usa la red esa información para mejorar?
La respuesta está en uno de los algoritmos más importantes del aprendizaje automático: el descenso del gradiente, o Gradient Descent.
Este algoritmo permite ajustar los parámetros del modelo, como pesos y bias, para que la pérdida sea cada vez menor. En otras palabras, es uno de los mecanismos centrales que hacen posible el aprendizaje en Deep Learning.
10.2 ¿Qué problema resuelve el descenso del gradiente?
Una red neuronal tiene muchos parámetros. Al comienzo del entrenamiento, esos parámetros suelen tener valores aleatorios, por lo que la red comete errores importantes. El objetivo es encontrar mejores valores para esos parámetros de modo que la pérdida disminuya.
Podemos pensar esto como un problema de optimización:
El descenso del gradiente es justamente un procedimiento para acercarse a esa solución.
10.3 La intuición de una montaña
Una forma muy útil de entender el descenso del gradiente es imaginar un paisaje con montañas y valles. Supongamos que estás parado en una ladera y quieres llegar al punto más bajo del terreno.
Si pudieras mirar a tu alrededor y detectar hacia dónde el terreno desciende más, entonces podrías dar un pequeño paso en esa dirección. Si repites este proceso muchas veces, poco a poco bajarás hacia una zona más baja.
En esta analogía:
- La altura del terreno representa la pérdida.
- Tu posición representa los valores actuales de los parámetros.
- Bajar por la pendiente representa ajustar los parámetros para reducir la pérdida.
10.4 ¿Qué es el gradiente?
Para saber hacia dónde bajar, el algoritmo necesita una medida de la pendiente. Esa medida es el gradiente.
El gradiente indica cómo cambia la función de pérdida cuando cambian los parámetros del modelo. Más precisamente, nos dice:
- En qué dirección aumenta más rápidamente la pérdida.
- Qué tan sensible es la pérdida a cambios en cada parámetro.
Como nosotros queremos reducir la pérdida, en lugar de movernos en la dirección del gradiente, nos movemos en la dirección contraria. Por eso se llama descenso del gradiente.
10.5 La idea central del algoritmo
El algoritmo sigue una lógica repetitiva muy simple:
- Calcula la pérdida actual.
- Calcula el gradiente de esa pérdida respecto de los parámetros.
- Ajusta los parámetros en dirección opuesta al gradiente.
- Repite el proceso muchas veces.
Con cada iteración, si todo funciona bien, la pérdida debería ir disminuyendo.
10.6 Actualización de parámetros
La regla de actualización del descenso del gradiente puede escribirse de manera conceptual así:
Esto significa que tomamos el valor actual del parámetro y le restamos una fracción del gradiente.
Esa fracción depende de un valor muy importante llamado tasa de aprendizaje.
10.7 ¿Qué es la tasa de aprendizaje?
La tasa de aprendizaje, o learning rate, controla el tamaño del paso que damos en cada actualización.
Si la tasa de aprendizaje es muy grande:
- Los cambios en los parámetros serán muy bruscos.
- Podríamos pasarnos del mínimo o volver inestable el entrenamiento.
Si la tasa de aprendizaje es muy pequeña:
- El entrenamiento avanzará muy lentamente.
- Puede tardar demasiado en llegar a una buena solución.
Elegir una buena tasa de aprendizaje es una de las decisiones más importantes del entrenamiento.
10.8 Ejemplo intuitivo de tasa de aprendizaje
Volvamos a la analogía de la montaña. Si das pasos demasiado grandes, puedes saltar de un lado al otro del valle sin estabilizarte. Si das pasos demasiado pequeños, bajarás con mucha lentitud.
La tasa de aprendizaje determina el equilibrio entre avanzar rápido y avanzar con estabilidad.
10.9 Descenso del gradiente en una dimensión
Imaginemos un caso muy simple con un solo parámetro. La función de pérdida depende solo de ese parámetro. En cada paso:
- Miramos la pendiente en el punto actual.
- Si la pendiente es positiva, nos movemos hacia la izquierda.
- Si la pendiente es negativa, nos movemos hacia la derecha.
Así vamos acercándonos a una zona donde la pendiente es pequeña y la pérdida es menor.
10.10 Descenso del gradiente en muchas dimensiones
En redes neuronales reales no hay un solo parámetro, sino miles o millones. Por eso, la optimización ocurre en un espacio de muchas dimensiones.
Aunque esto no puede visualizarse fácilmente, la idea sigue siendo la misma:
- Cada parámetro tiene su propio gradiente.
- Todos se actualizan en conjunto.
- La red intenta moverse hacia regiones de menor pérdida.
El principio matemático es el mismo, aunque el problema sea mucho más grande.
10.11 El proceso iterativo del entrenamiento
El descenso del gradiente no resuelve todo en un solo paso. El aprendizaje ocurre de manera gradual y repetitiva.
En cada iteración del entrenamiento:
- Se toma un conjunto de ejemplos.
- Se hace forward propagation.
- Se calcula la pérdida.
- Se obtienen gradientes.
- Se actualizan los parámetros.
Después de muchas iteraciones, el modelo suele mejorar sus predicciones.
10.12 El objetivo no siempre es el mínimo absoluto perfecto
En teoría, el descenso del gradiente busca un mínimo de la pérdida. En la práctica, no siempre llega al mínimo global perfecto, y eso no necesariamente es un problema.
En muchos casos basta con encontrar una región donde la pérdida sea suficientemente baja y el modelo generalice bien.
El objetivo práctico no es la perfección matemática absoluta, sino un modelo útil y estable.
10.13 Mínimos locales y mínimo global
En una función compleja pueden existir varios puntos bajos. El más bajo de todos se llama mínimo global. Otros puntos bajos, pero no los mejores posibles, se llaman mínimos locales.
En teoría, un algoritmo de optimización puede quedar atrapado en un mínimo local. En redes neuronales profundas la situación es más compleja, pero esta idea sigue siendo útil para entender que la optimización no siempre encuentra la solución ideal absoluta.
10.14 Descenso del gradiente por lotes completos (Batch Gradient Descent)
Una forma de aplicar el algoritmo es calcular la pérdida y el gradiente usando todo el conjunto de entrenamiento a la vez. Esto se conoce como Batch Gradient Descent.
Ventajas:
- La dirección del gradiente es estable.
- Usa toda la información disponible en cada paso.
Desventajas:
- Puede ser muy costoso si el conjunto de datos es grande.
- Cada actualización puede tardar demasiado.
10.15 Descenso del gradiente estocástico (SGD)
Otra opción es actualizar los parámetros usando un solo ejemplo a la vez. Esto se conoce como Stochastic Gradient Descent, o SGD.
Ventajas:
- Las actualizaciones son rápidas.
- Puede explorar mejor el espacio de soluciones.
Desventajas:
- El camino hacia el mínimo es más ruidoso.
- Las actualizaciones pueden ser inestables.
Aun así, SGD y sus variantes son extremadamente importantes en Deep Learning.
10.16 Mini-batch Gradient Descent
En la práctica, la estrategia más usada suele ser un punto intermedio: el mini-batch gradient descent. En lugar de usar todo el dataset o un solo ejemplo, se usan pequeños lotes de datos.
Esto combina ventajas de los dos enfoques anteriores:
- Más eficiencia que usar el dataset completo.
- Más estabilidad que usar un único ejemplo.
Por eso, cuando entrenamos modelos modernos, normalmente trabajamos con batches de tamaño intermedio.
10.17 Relación con épocas y batches
Conviene conectar este tema con otros conceptos del entrenamiento:
- Un batch es un grupo de ejemplos procesados juntos.
- Una época es una pasada completa por todo el conjunto de entrenamiento.
Durante cada época, el descenso del gradiente realiza muchas actualizaciones, una por cada batch procesado.
10.18 Qué pasa si la tasa de aprendizaje es demasiado alta
Si la tasa de aprendizaje es excesiva, el algoritmo puede volverse inestable. En lugar de acercarse al mínimo, puede:
- Saltar de un lado a otro.
- No converger.
- Incluso empeorar la pérdida.
En estos casos, el entrenamiento puede fallar o producir resultados erráticos.
10.19 Qué pasa si la tasa de aprendizaje es demasiado baja
Si la tasa de aprendizaje es demasiado pequeña, el algoritmo puede mejorar, pero de manera muy lenta. El entrenamiento puede requerir mucho tiempo para llegar a una solución útil.
En problemas grandes, esto puede volver el proceso poco práctico.
10.20 Una analogía con estudiar para un examen
Podemos pensar el descenso del gradiente como un estudiante que ajusta su método de estudio según los errores de un examen de práctica.
- La pérdida indica cuánto se equivocó.
- El gradiente le dice en qué dirección conviene corregirse.
- La tasa de aprendizaje indica cuán drástico será el cambio en su estrategia.
Si cambia demasiado, puede perder lo que ya funcionaba. Si cambia demasiado poco, tardará mucho en mejorar. La clave está en ajustar con criterio.
10.21 Descenso del gradiente y backpropagation
Es importante diferenciar dos conceptos que suelen aparecer juntos:
- Backpropagation: calcula los gradientes.
- Gradient Descent: usa esos gradientes para actualizar parámetros.
Es decir:
- Backpropagation responde: "¿cómo afecta cada parámetro a la pérdida?"
- Gradient Descent responde: "¿cómo actualizo el parámetro usando esa información?"
Ambos trabajan juntos durante el entrenamiento.
10.22 Optimizadores modernos
Aunque el descenso del gradiente básico es la idea central, en la práctica suelen usarse versiones mejoradas llamadas optimizadores. Algunos muy conocidos son:
- SGD (Stochastic Gradient Descent)
- Momentum
- RMSprop (Root Mean Square Propagation)
- Adam (Adaptive Moment Estimation)
Estos métodos agregan mejoras para hacer el aprendizaje más estable o más rápido. Sin embargo, todos parten de la idea básica de moverse en dirección opuesta al gradiente.
10.23 Por qué el descenso del gradiente funciona tan bien
La razón principal es que ofrece una forma sistemática de mejorar gradualmente los parámetros del modelo usando información local de la pérdida.
No necesita conocer toda la estructura del problema de una sola vez. Le basta con saber, en cada punto, hacia dónde conviene moverse para bajar.
Esa simplicidad, combinada con el poder del cálculo diferencial y el cómputo moderno, lo convirtió en una de las bases del Deep Learning.
10.24 Limitaciones prácticas
Aunque es muy poderoso, el descenso del gradiente no es mágico. Algunas dificultades prácticas incluyen:
- Elegir una buena tasa de aprendizaje.
- Lidiar con superficies de pérdida complejas.
- Evitar entrenamientos demasiado lentos o inestables.
- Encontrar un buen equilibrio entre velocidad y precisión.
Por eso suelen usarse estrategias complementarias y optimizadores más avanzados.
10.25 Relación con PyTorch
En PyTorch, el descenso del gradiente y sus variantes se implementan mediante optimizadores. Más adelante usaremos componentes como:
torch.optim.SGDtorch.optim.Adam
Estos optimizadores automatizan la actualización de parámetros a partir de los gradientes calculados durante el entrenamiento.
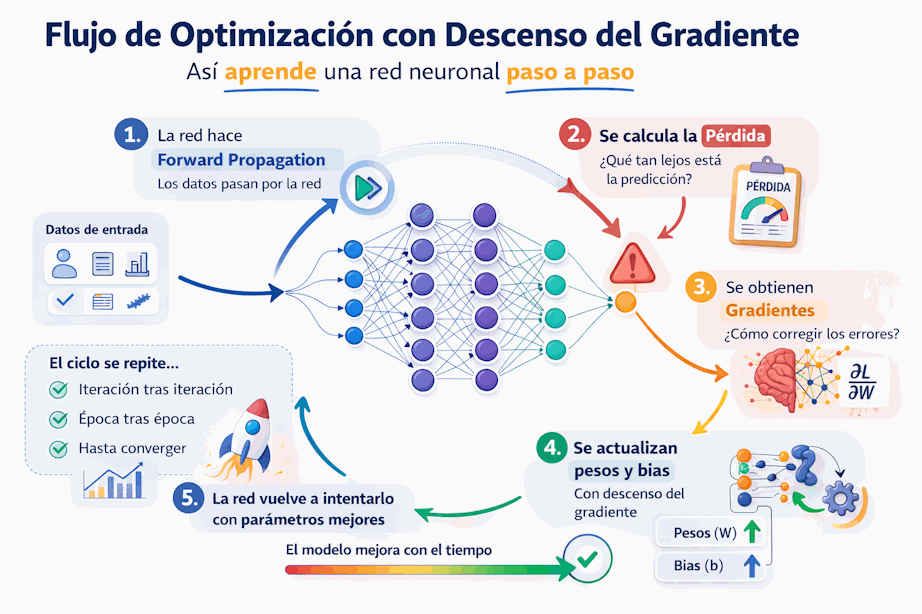
10.26 Resumen del flujo de optimización
Podemos resumir el papel del descenso del gradiente dentro del entrenamiento así:
- La red hace forward propagation.
- Se calcula la pérdida.
- Se obtienen gradientes.
- Se actualizan pesos y bias con descenso del gradiente.
- La red vuelve a intentarlo con parámetros ligeramente mejores.
Este ciclo se repite una y otra vez hasta que el modelo mejora lo suficiente.
10.27 Qué debes recordar de este tema
- El descenso del gradiente es un algoritmo de optimización.
- Su objetivo es reducir la función de pérdida.
- Utiliza gradientes para decidir cómo actualizar los parámetros.
- La tasa de aprendizaje controla el tamaño del paso.
- Puede aplicarse en modo batch, estocástico o mini-batch.
- Backpropagation calcula gradientes; gradient descent actualiza parámetros.
- Optimizadores como SGD y Adam son variantes prácticas de esta idea.
- El aprendizaje de la red ocurre repitiendo muchas veces este proceso.
10.28 Conclusión
El descenso del gradiente es uno de los pilares del entrenamiento de redes neuronales. Gracias a él, la red puede usar la información que aporta la función de pérdida para corregirse de manera progresiva.
Entender este algoritmo es fundamental porque conecta la noción de error con la mejora real del modelo. El siguiente paso natural será profundizar en cómo se calculan esos gradientes de manera eficiente mediante backpropagation.