11. Backpropagation explicado paso a paso
11.1 Introducción
Ya vimos que una red neuronal hace una predicción mediante la propagación hacia adelante, que la función de pérdida mide qué tan equivocada está y que el descenso del gradiente actualiza los parámetros para mejorar. Pero todavía falta una pieza esencial del rompecabezas: ¿cómo sabe la red cuánto debe corregir cada peso?
La respuesta está en backpropagation, o retropropagación del error. Este algoritmo permite calcular cómo influye cada parámetro en la pérdida final y, por lo tanto, cómo conviene ajustarlo.
Backpropagation es una de las ideas más importantes de todo el Deep Learning. Sin él, entrenar redes neuronales profundas de manera eficiente sería prácticamente inviable.
11.2 ¿Qué es backpropagation?
Backpropagation es un procedimiento matemático que calcula los gradientes de la función de pérdida con respecto a los parámetros de la red, propagando esa información desde la salida hacia las capas anteriores.
Dicho de una forma más intuitiva:
- La red primero hace una predicción.
- Luego compara esa predicción con el valor correcto.
- Después distribuye el error hacia atrás para saber cuánto contribuyó cada parte de la red a ese error.
Gracias a eso, cada peso puede corregirse de manera informada.
11.3 ¿Por qué es necesario?
Imaginemos una red neuronal con muchas capas y miles de pesos. Si la predicción final es incorrecta, necesitamos responder preguntas como estas:
- ¿Qué peso contribuyó más al error?
- ¿Qué peso debería aumentar?
- ¿Qué peso debería disminuir?
- ¿En qué magnitud habría que cambiar cada uno?
No basta con saber que la red se equivocó. Necesitamos saber cómo repartir la responsabilidad del error entre todos los parámetros. Eso es lo que hace backpropagation.
11.4 Relación con gradient descent
Es muy importante distinguir entre backpropagation y descenso del gradiente:
- Backpropagation calcula los gradientes.
- Gradient Descent usa esos gradientes para actualizar los parámetros.
En otras palabras:
- Backpropagation responde: "¿cuánto influye este parámetro en la pérdida?"
- Gradient Descent responde: "¿cómo actualizo este parámetro usando esa información?"
Ambos procesos trabajan juntos dentro del entrenamiento.
11.5 La idea central: propagar el error hacia atrás
Cuando la red produce una salida incorrecta, el error se observa primero al final, en la capa de salida. A partir de ahí, backpropagation lleva esa información hacia las capas anteriores.
Esto tiene lógica:
- Primero sabemos cuánto se equivocó la salida final.
- Luego calculamos cuánto contribuyó cada neurona anterior a ese error.
- Después calculamos cuánto contribuyó cada peso.
Así, el error “viaja” hacia atrás por la red.
11.6 La regla de la cadena
El fundamento matemático de backpropagation es la regla de la cadena, una herramienta del cálculo diferencial. Esta regla permite derivar funciones compuestas.
Y una red neuronal, justamente, puede verse como una gran composición de funciones:
- Entradas
- Sumas ponderadas
- Activaciones
- Nuevas sumas
- Nuevas activaciones
- Salida final
La regla de la cadena permite descomponer cómo afecta cada parte intermedia al resultado final.
11.7 Una intuición simple de la regla de la cadena
Si una variable afecta a otra, y esa segunda variable afecta a una tercera, entonces la primera también afecta indirectamente a la tercera. La regla de la cadena cuantifica justamente ese efecto indirecto.
En una red neuronal, un peso de una capa inicial no afecta directamente a la pérdida, pero sí influye en neuronas intermedias, que luego afectan otras neuronas y finalmente la salida. Backpropagation sigue ese camino hacia atrás para medir ese impacto total.
11.8 Estructura general del entrenamiento
Para ubicar backpropagation dentro del entrenamiento, podemos resumir el proceso completo así:
- La red recibe una entrada.
- Hace forward propagation y genera una predicción.
- Se calcula la pérdida comparando con el valor real.
- Se ejecuta backpropagation para calcular gradientes.
- Se actualizan los parámetros con un optimizador como gradient descent.
Backpropagation es, por lo tanto, el puente entre la pérdida y la actualización de parámetros.
11.9 Un ejemplo conceptual con una sola neurona
Supongamos una neurona muy simple con:
- una entrada
x, - un peso
w, - un bias
b, - una salida
y_pred.
La neurona calcula una predicción y luego comparamos esa predicción con el valor real y.
Si la pérdida es alta, backpropagation calcula:
- cuánto influyó
wen la pérdida, - cuánto influyó
ben la pérdida.
Con esa información ya podemos corregir ambos parámetros.
11.10 Qué significa calcular un gradiente
Calcular el gradiente de la pérdida respecto de un parámetro significa responder esta pregunta:
Si el gradiente es positivo, aumentar ese parámetro hará subir la pérdida, por lo que conviene reducirlo. Si el gradiente es negativo, aumentarlo puede ayudar a bajar la pérdida.
Esa es la información que usa el descenso del gradiente para actualizar los parámetros.
11.11 Qué ocurre en la capa de salida
Backpropagation comienza en la capa de salida, porque allí es donde primero podemos medir el error de manera directa.
En esa capa:
- Se compara la predicción con el valor real.
- Se calcula cómo cambia la pérdida respecto de la salida.
- Se calcula cómo esa salida depende de los pesos y bias de la capa final.
Con eso se obtienen los primeros gradientes.
11.12 Qué ocurre en una capa oculta
Las capas ocultas no se comparan directamente con la respuesta real. Entonces, ¿cómo saben cuánto se equivocaron?
La respuesta es que reciben esa información desde las capas siguientes. Backpropagation usa el error calculado en capas posteriores para estimar cuánto contribuyó cada neurona oculta al error final.
De esta forma, el error se propaga hacia atrás capa por capa.
11.13 Intuición de la responsabilidad del error
Podemos imaginar la red como una cadena de decisiones. Si el resultado final fue malo, queremos saber qué parte de la cadena fue más responsable.
Backpropagation hace precisamente eso: distribuye la responsabilidad del error entre neuronas y pesos según cuánto influyeron en el resultado final.
11.14 Paso a paso conceptual de backpropagation
- La red calcula una predicción mediante forward propagation.
- Se mide la pérdida.
- Se calcula el error en la salida final.
- Ese error se propaga hacia la capa anterior.
- En cada capa se calcula el efecto de sus neuronas sobre el error.
- Se obtienen gradientes para cada peso y bias.
- El optimizador usa esos gradientes para actualizar parámetros.
Este proceso se repite miles o millones de veces durante el entrenamiento.
11.15 El papel de las activaciones en backpropagation
Las funciones de activación no solo influyen en la propagación hacia adelante; también afectan cómo se calculan los gradientes durante la propagación hacia atrás.
Por eso la elección de activaciones es tan importante. Algunas activaciones facilitan más el aprendizaje que otras porque permiten un flujo de gradientes más útil y estable.
Esto se relaciona directamente con problemas como el gradiente muy pequeño o la saturación de ciertas funciones.
11.16 Backpropagation y eficiencia
Una de las grandes virtudes de backpropagation es que permite calcular gradientes de forma eficiente, reutilizando información intermedia de la red. No hace falta recalcular todo desde cero para cada parámetro.
Esto es crucial porque las redes modernas pueden tener millones de parámetros. Sin un procedimiento eficiente, el entrenamiento sería demasiado lento o directamente impracticable.
11.17 Un ejemplo intuitivo con dos capas
Imaginemos una red con:
- una capa oculta,
- una capa de salida.
Si la salida final fue incorrecta:
- Primero calculamos cuánto error hubo en la salida.
- Luego calculamos cuánto aportó cada neurona oculta a esa salida.
- Después calculamos cuánto aportó cada peso que llega a esas neuronas ocultas.
Es decir, el error va retrocediendo desde la salida hacia la entrada.
11.18 Backpropagation no actualiza parámetros por sí solo
Conviene insistir en esta distinción: backpropagation calcula gradientes, pero no actualiza los pesos por sí mismo. La actualización ocurre después, cuando interviene el optimizador.
Esto es importante porque a veces se piensa erróneamente que backpropagation “entrena solo” la red. En realidad, forma parte del proceso, pero no lo completa por sí mismo.
11.19 Relación con la tasa de aprendizaje
Los gradientes que produce backpropagation indican dirección e intensidad del cambio, pero la magnitud real de la actualización depende de la tasa de aprendizaje.
Así, el flujo completo sería:
- Backpropagation dice cuánto influye cada parámetro en la pérdida.
- Gradient Descent usa esa información y la combina con la tasa de aprendizaje para modificar el parámetro.
11.20 Problema del gradiente desvanecido
Uno de los problemas clásicos relacionados con backpropagation es el gradiente desvanecido. Ocurre cuando, al propagarse hacia atrás, los gradientes se hacen cada vez más pequeños y las capas iniciales aprenden muy lentamente.
Este problema fue una de las razones por las que entrenar redes profundas era tan difícil en ciertas épocas. El uso de mejores activaciones, mejores inicializaciones y mejores arquitecturas ayudó a mitigar este inconveniente.
11.21 Problema del gradiente explosivo
El caso opuesto también puede ocurrir: a veces los gradientes crecen demasiado al propagarse hacia atrás. Eso se conoce como gradiente explosivo.
Cuando pasa, las actualizaciones pueden volverse inestables y el entrenamiento puede divergir.
Esto muestra que el flujo de gradientes es una parte delicada del entrenamiento y que no basta con aplicar backpropagation; también hay que hacerlo en un contexto adecuado.
11.22 Por qué fue un avance histórico tan importante
Históricamente, la posibilidad de entrenar redes multicapa de forma eficiente fue uno de los grandes factores que permitieron el desarrollo posterior del Deep Learning. Backpropagation dio una respuesta práctica al problema de cómo repartir el error a través de muchas capas.
Sin esta idea, las redes profundas no habrían podido convertirse en la tecnología central que son hoy.
11.23 Relación con PyTorch
En PyTorch, uno de los grandes beneficios es que no necesitamos programar a mano toda la matemática de backpropagation para modelos comunes. La biblioteca utiliza diferenciación automática, lo que permite calcular gradientes automáticamente.
Esto no significa que backpropagation desaparezca. Significa que PyTorch lo ejecuta por nosotros cuando definimos correctamente el modelo y la pérdida.
Por eso es tan importante entender el concepto, aunque luego el framework automatice gran parte del trabajo.
11.24 Qué significa diferenciación automática
La diferenciación automática es un mecanismo por el cual bibliotecas como PyTorch registran las operaciones realizadas durante el forward propagation y luego pueden calcular gradientes de forma automática durante el backward.
En términos prácticos:
- Tú defines el modelo.
- Tú calculas la pérdida.
- PyTorch calcula los gradientes.
Pero, conceptualmente, ese cálculo automático sigue estando basado en backpropagation y regla de la cadena.
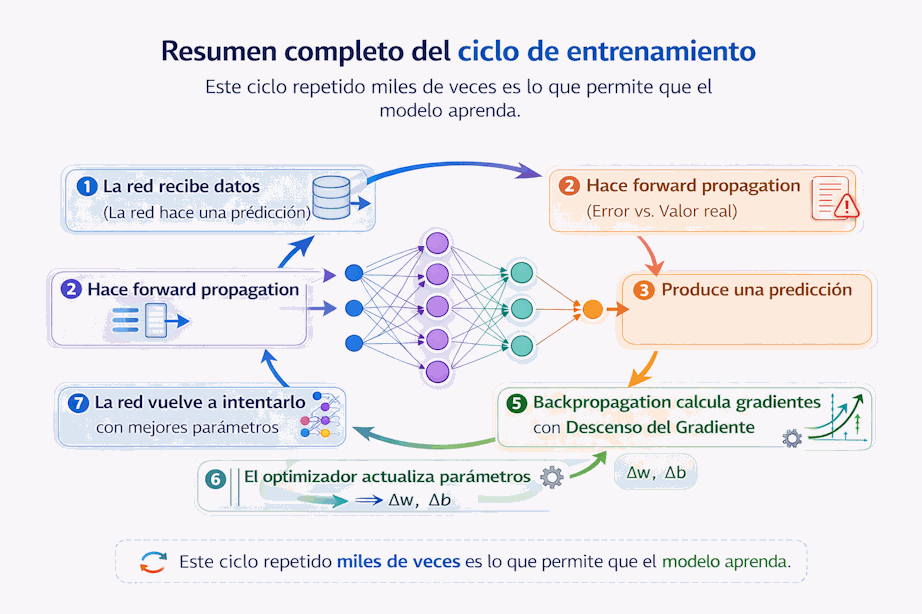
11.25 Un resumen completo del ciclo
Podemos resumir el ciclo de entrenamiento así:
- La red recibe datos.
- Hace forward propagation.
- Produce una predicción.
- Se calcula la pérdida.
- Backpropagation calcula gradientes.
- El optimizador actualiza parámetros.
- La red vuelve a intentarlo con parámetros mejorados.
Este ciclo repetido miles de veces es lo que permite que el modelo aprenda.
11.26 Qué debes recordar de este tema
- Backpropagation calcula gradientes de la pérdida respecto de los parámetros.
- Propaga el error desde la salida hacia las capas anteriores.
- Se apoya matemáticamente en la regla de la cadena.
- Permite saber cuánto contribuyó cada peso al error final.
- No actualiza parámetros por sí solo; eso lo hace el optimizador.
- Es una pieza central del entrenamiento de redes neuronales.
- Problemas como gradiente desvanecido o explosivo están relacionados con este proceso.
- PyTorch automatiza este cálculo mediante diferenciación automática.
11.27 Conclusión
Backpropagation es uno de los conceptos más importantes del Deep Learning porque explica cómo una red neuronal reparte el error entre sus millones de parámetros para poder corregirse.
Comprender este proceso es clave porque conecta la pérdida con el aprendizaje real del modelo. Con esta base, ya estamos en condiciones de pasar de la teoría general del aprendizaje a la práctica concreta del trabajo con PyTorch.