24. Introducción a redes convolucionales (CNN)
24.1 Introducción
Hasta ahora hemos trabajado principalmente con redes densas o multicapa, como los MLP. Esas redes son muy útiles, especialmente para datos tabulares.
Sin embargo, cuando pasamos al mundo de las imágenes, aparece una dificultad importante: las imágenes tienen estructura espacial. No son solo listas de números sin relación entre sí.
Ahí entran en juego las redes convolucionales, conocidas como CNN por Convolutional Neural Networks.
24.2 Por qué un MLP no es ideal para imágenes grandes
Imagina una imagen de 100 por 100 píxeles en escala de grises. Eso ya son 10.000 valores de entrada.
Si conectáramos esos 10.000 valores a una capa densa grande, el número de parámetros crecería muchísimo.
Además, esa capa densa no aprovecharía bien el hecho de que píxeles cercanos suelen estar relacionados entre sí.
24.3 La idea central de una CNN
La idea fundamental de una CNN es usar filtros pequeños que recorren la imagen y detectan patrones locales.
En lugar de conectar todo con todo desde el principio, la red aprende detectores de bordes, formas, texturas y patrones más complejos.
Esto hace que la arquitectura sea más eficiente y, al mismo tiempo, mucho más adecuada para datos visuales.
24.4 Qué es una convolución
En términos simples, una convolución consiste en aplicar un pequeño filtro o kernel sobre distintas regiones de la imagen.
Ese filtro va recorriendo la imagen y produce una nueva representación.
La salida de este proceso suele llamarse mapa de características o feature map.
24.5 Pensar el filtro como detector
Una forma intuitiva de verlo es esta: cada filtro funciona como un detector especializado.
Un filtro puede volverse bueno detectando bordes horizontales, otro bordes verticales, otro pequeñas esquinas, otro manchas o texturas.
La red no recibe esos detectores ya construidos: los aprende durante el entrenamiento.
24.6 Ventaja del peso compartido
En una CNN, el mismo filtro se aplica en muchas posiciones distintas de la imagen.
Eso significa que no se aprende un conjunto distinto de pesos para cada zona, sino que se comparte el mismo detector a lo largo del espacio.
Esta idea se conoce como compartición de pesos y es una de las claves de la eficiencia de las CNN.
24.7 Receptive field o campo receptivo
Cada neurona de una capa convolucional no “mira” toda la imagen de una vez, sino una pequeña región local.
Esa región local se llama campo receptivo.
Al apilar varias capas convolucionales, la red puede ir combinando información local para construir patrones cada vez más complejos y de mayor alcance.
24.8 Qué produce una capa convolucional
Cuando una imagen entra en una capa convolucional, la salida ya no es una imagen igual a la original, sino un conjunto de mapas de características.
Cada filtro aprendido genera un mapa distinto.
Por eso, si una capa tiene 8 filtros, la salida tendrá 8 canales de activaciones.
24.9 Convolución y activación
Después de la convolución, suele aplicarse una función de activación como ReLU.
Esto introduce no linealidad, igual que en los MLP.
Sin activaciones no lineales, la red perdería gran parte de su capacidad de modelado.
24.10 Qué es el pooling
Otra operación muy común en CNN es el pooling.
El pooling reduce el tamaño espacial de los mapas de características. Por ejemplo, puede tomar bloques pequeños y quedarse con el valor máximo.
Esto ayuda a resumir información, reducir costo computacional y ganar cierta robustez frente a pequeños desplazamientos.
24.11 Max Pooling
La forma más conocida es Max Pooling.
Por ejemplo, si tomamos una ventana 2x2 y aplicamos max pooling, nos quedamos con el valor más alto de esa región.
La idea es conservar la activación más fuerte, que muchas veces representa la presencia más clara de un patrón detectado.
24.12 Una CNN típica
Una CNN sencilla suele seguir una lógica como esta:
Primero se extraen patrones locales, luego se resumen y, al final, se pasa a una parte densa que toma decisiones de clasificación o regresión.
24.13 Qué significa flatten
Después de varias capas convolucionales y de pooling, la salida suele seguir teniendo forma multidimensional.
Si queremos conectarla a capas densas finales, necesitamos aplanarla en un vector.
Esa operación se suele llamar flatten.
24.14 CNN no es solo para imágenes
Aunque las CNN son especialmente famosas en visión por computadora, la idea de convolución también puede aplicarse a otras estructuras.
Por ejemplo, existen convoluciones sobre señales, audio y algunas secuencias temporales.
Sin embargo, en esta introducción nos concentraremos en su uso más clásico: imágenes.
24.15 Por qué las CNN fueron tan importantes
Las CNN tuvieron un impacto enorme porque permitieron mejorar notablemente el procesamiento automático de imágenes.
Su capacidad para aprender detectores visuales directamente a partir de datos transformó áreas como clasificación de imágenes, detección de objetos y reconocimiento visual en general.
Durante muchos años fueron una de las arquitecturas centrales del Deep Learning aplicado a visión.
24.16 Diferencia con una capa densa
Podemos resumir una diferencia importante así:
- Capa densa: conecta todo con todo.
- Capa convolucional: trabaja localmente y comparte filtros.
Esa diferencia cambia radicalmente la forma en que el modelo procesa imágenes.
24.17 Qué hiperparámetros aparecen en una CNN
En una CNN aparecen varios hiperparámetros importantes:
- Número de filtros.
- Tamaño del kernel.
- Stride o paso.
- Padding.
- Tamaño del pooling.
Estos valores afectan la forma de la salida y la capacidad de la red para capturar patrones.
24.18 Qué es el stride
El stride indica cuánto avanza el filtro cada vez que se desplaza sobre la imagen.
Si el stride es 1, el filtro avanza de a una posición. Si es 2, salta más.
Esto influye en el tamaño del mapa de salida y en cuánta información espacial conserva la capa.
24.19 Qué es el padding
El padding consiste en agregar bordes artificiales alrededor de la imagen, usualmente con ceros.
Esto puede servir para controlar el tamaño de la salida y para no perder tan rápidamente información de los bordes.
En PyTorch suele especificarse directamente como parte de la capa convolucional.
24.20 Cómo se escribe una convolución en PyTorch
En PyTorch, una capa convolucional 2D típica se define con nn.Conv2d.
Aquí estamos diciendo que la entrada tiene 1 canal, la capa aprenderá 8 filtros, el kernel será 3x3 y se usará padding 1.
24.21 Qué son los canales
En imágenes en escala de grises suele haber 1 canal. En imágenes RGB suele haber 3 canales: rojo, verde y azul.
Las capas convolucionales trabajan teniendo en cuenta esos canales.
Por eso, el parámetro in_channels debe coincidir con la estructura de la entrada.
24.22 Qué observaremos en la aplicación final
En la aplicación final no usaremos un dataset externo pesado, porque el objetivo aquí es entender la estructura de una CNN de manera sencilla.
En cambio, generaremos imágenes pequeñas sintéticas de 8x8 píxeles pertenecientes a tres clases:
- Imágenes con una barra vertical.
- Imágenes con una barra horizontal.
- Imágenes con una barra oblicua.
Luego entrenaremos una CNN para distinguir estas tres clases.
24.23 Por qué este ejemplo es didáctico
Este problema es simple, pero muy útil para aprender.
Permite ver claramente que la red está trabajando con estructura espacial, algo que sería menos natural de apreciar en un ejemplo puramente tabular.
Además, como las imágenes son pequeñas, el código resulta accesible para alguien que está viendo CNN por primera vez.
24.24 Código completo para ejecutar
En este punto conviene trabajar con dos versiones de la aplicación.
La primera versión es la más importante desde el punto de vista didáctico: contiene solo las partes esenciales para entender cómo se genera el dataset, cómo se define la CNN y cómo se entrena.
La segunda versión reutiliza la misma idea, pero agrega una interfaz visual con Tkinter para que el usuario pueda dibujar líneas verticales, horizontales y oblicuas y luego pedir una predicción al modelo.
Versión 1: código mínimo para entender una CNN
import torch
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(24)
torch.set_printoptions(precision=2, sci_mode=False)
def generar_imagen_vertical():
col = torch.randint(1, 7, (1,)).item()
matriz = [
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0]
]
for fila in range(8):
matriz[fila][col] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_imagen_horizontal():
fila = torch.randint(1, 7, (1,)).item()
matriz = [
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0]
]
for col in range(8):
matriz[fila][col] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_imagen_oblicua():
matriz = [
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0]
]
tipo = torch.randint(0, 2, (1,)).item()
if tipo == 0:
for i in range(8):
matriz[i][i] = 1
else:
for i in range(8):
matriz[i][7 - i] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_dataset(n_por_clase):
imagenes = []
etiquetas = []
for _ in range(n_por_clase):
imagenes.append(generar_imagen_vertical())
etiquetas.append(0)
imagenes.append(generar_imagen_horizontal())
etiquetas.append(1)
imagenes.append(generar_imagen_oblicua())
etiquetas.append(2)
X = torch.stack(imagenes).unsqueeze(1) # [N, 1, 8, 8]
y = torch.tensor(etiquetas, dtype=torch.long)
return X, y
X_train, y_train = generar_dataset(120)
X_val, y_val = generar_dataset(60)
class CNNPequena(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2)
self.fc1 = nn.Linear(16 * 2 * 2, 16)
self.fc2 = nn.Linear(16, 3)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
def calcular_accuracy(logits, y_real):
pred = torch.argmax(logits, dim=1)
return (pred == y_real).float().mean().item()
modelo = CNNPequena()
criterio = nn.CrossEntropyLoss()
optimizador = optim.Adam(modelo.parameters(), lr=0.01)
for epoca in range(120):
modelo.train()
logits_train = modelo(X_train)
loss_train = criterio(logits_train, y_train)
optimizador.zero_grad()
loss_train.backward()
optimizador.step()
if (epoca + 1) % 20 == 0:
modelo.eval()
with torch.no_grad():
logits_train_eval = modelo(X_train)
logits_val = modelo(X_val)
train_loss = criterio(logits_train_eval, y_train).item()
val_loss = criterio(logits_val, y_val).item()
train_acc = calcular_accuracy(logits_train_eval, y_train)
val_acc = calcular_accuracy(logits_val, y_val)
print(f"Epoca {epoca+1:3d} | train loss={train_loss:.4f} | val loss={val_loss:.4f} | train acc={train_acc:.3f} | val acc={val_acc:.3f}")
modelo.eval()
with torch.no_grad():
logits_train = modelo(X_train)
logits_val = modelo(X_val)
train_loss = criterio(logits_train, y_train).item()
val_loss = criterio(logits_val, y_val).item()
train_acc = calcular_accuracy(logits_train, y_train)
val_acc = calcular_accuracy(logits_val, y_val)
print()
print("RESUMEN FINAL")
print(f"train loss={train_loss:.4f} | val loss={val_loss:.4f}")
print(f"train acc={train_acc:.3f} | val acc={val_acc:.3f}")
ejemplos_nuevos = torch.stack([
generar_imagen_vertical(),
generar_imagen_horizontal(),
generar_imagen_oblicua()
]).unsqueeze(1)
nombres_clases = ["vertical", "horizontal", "oblicua"]
with torch.no_grad():
logits = modelo(ejemplos_nuevos)
probs = torch.softmax(logits, dim=1)
predicciones = torch.argmax(probs, dim=1)
print()
print("Probabilidades para imagenes nuevas:")
print(probs)
print()
print("Predicciones finales:")
for i in range(len(predicciones)):
clase = predicciones[i].item()
print(f"Imagen {i+1}: {nombres_clases[clase]}")Esta primera versión es la recomendable para estudiar la arquitectura sin distracciones visuales.
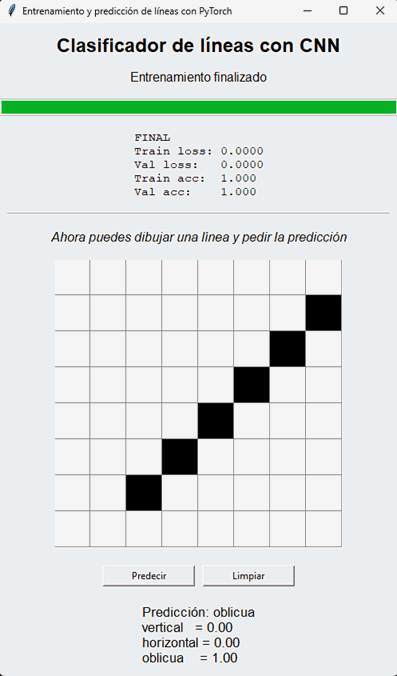
Versión 2: aplicación visual con dibujo interactivo
Si además queremos una aplicación más atractiva, podemos sumar una interfaz gráfica donde se entrena el modelo y luego se habilita una cuadrícula para dibujar la línea manualmente.
import tkinter as tk
from tkinter import messagebox, ttk
import torch
import torch.nn as nn
import torch.optim as optim
# ---------------------------------------------------------
# Configuración general
# ---------------------------------------------------------
torch.manual_seed(24)
torch.set_printoptions(precision=2, sci_mode=False)
# ---------------------------------------------------------
# Generación de imágenes sintéticas
# ---------------------------------------------------------
def generar_imagen_vertical():
col = torch.randint(1, 7, (1,)).item()
matriz = [[0 for _ in range(8)] for _ in range(8)]
for fila in range(8):
matriz[fila][col] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_imagen_horizontal():
fila = torch.randint(1, 7, (1,)).item()
matriz = [[0 for _ in range(8)] for _ in range(8)]
for col in range(8):
matriz[fila][col] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_imagen_oblicua():
matriz = [[0 for _ in range(8)] for _ in range(8)]
tipo = torch.randint(0, 2, (1,)).item()
if tipo == 0:
for i in range(8):
matriz[i][i] = 1
else:
for i in range(8):
matriz[i][7 - i] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_dataset(n_por_clase):
imagenes = []
etiquetas = []
for _ in range(n_por_clase):
imagenes.append(generar_imagen_vertical())
etiquetas.append(0)
imagenes.append(generar_imagen_horizontal())
etiquetas.append(1)
imagenes.append(generar_imagen_oblicua())
etiquetas.append(2)
X = torch.stack(imagenes).unsqueeze(1) # [N, 1, 8, 8]
y = torch.tensor(etiquetas, dtype=torch.long)
return X, y
# ---------------------------------------------------------
# Modelo
# ---------------------------------------------------------
class CNNPequena(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2)
self.fc1 = nn.Linear(16 * 2 * 2, 16)
self.fc2 = nn.Linear(16, 3)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
def calcular_accuracy(logits, y_real):
pred = torch.argmax(logits, dim=1)
return (pred == y_real).float().mean().item()
# ---------------------------------------------------------
# Aplicación Tkinter
# ---------------------------------------------------------
class AplicacionDibujo:
def __init__(self, ventana):
self.ventana = ventana
self.ventana.title("Entrenamiento y predicción de líneas con PyTorch")
self.filas = 8
self.columnas = 8
self.tamano_celda = 45
self.nombres_clases = ["vertical", "horizontal", "oblicua"]
self.total_epocas = 120
self.epoca_actual = 0
self.matriz = [[0 for _ in range(self.columnas)] for _ in range(self.filas)]
self.X_train = None
self.y_train = None
self.X_val = None
self.y_val = None
self.modelo = None
self.criterio = None
self.optimizador = None
self.crear_interfaz()
self.preparar_entrenamiento()
self.ventana.after(300, self.entrenar_paso)
def crear_interfaz(self):
self.label_titulo = tk.Label(
self.ventana,
text="Clasificador de líneas con CNN",
font=("Arial", 18, "bold")
)
self.label_titulo.pack(pady=(10, 5))
self.label_estado = tk.Label(
self.ventana,
text="Preparando entrenamiento...",
font=("Arial", 12)
)
self.label_estado.pack(pady=5)
self.barra = ttk.Progressbar(
self.ventana,
orient="horizontal",
length=500,
mode="determinate",
maximum=self.total_epocas
)
self.barra.pack(pady=10)
self.label_metricas = tk.Label(
self.ventana,
text="Métricas aún no disponibles",
font=("Courier New", 11),
justify="left"
)
self.label_metricas.pack(pady=5)
separador = tk.Frame(self.ventana, height=2, bd=1, relief="sunken")
separador.pack(fill="x", padx=10, pady=10)
self.label_dibujo = tk.Label(
self.ventana,
text="La interfaz de dibujo se activará al finalizar el entrenamiento",
font=("Arial", 12, "italic")
)
self.label_dibujo.pack(pady=5)
self.canvas = tk.Canvas(
self.ventana,
width=self.columnas * self.tamano_celda,
height=self.filas * self.tamano_celda,
bg="white"
)
self.canvas.pack(padx=10, pady=10)
self.rectangulos = []
for fila in range(self.filas):
fila_rects = []
for col in range(self.columnas):
x1 = col * self.tamano_celda
y1 = fila * self.tamano_celda
x2 = x1 + self.tamano_celda
y2 = y1 + self.tamano_celda
rect = self.canvas.create_rectangle(
x1, y1, x2, y2,
fill="white",
outline="gray"
)
fila_rects.append(rect)
self.rectangulos.append(fila_rects)
self.canvas.bind("<Button-1>", lambda e: None)
self.canvas.bind("<B1-Motion>", lambda e: None)
self.marco_botones = tk.Frame(self.ventana)
self.marco_botones.pack(pady=10)
self.boton_predecir = tk.Button(
self.marco_botones,
text="Predecir",
width=15,
command=self.predecir,
state="disabled"
)
self.boton_predecir.grid(row=0, column=0, padx=5)
self.boton_limpiar = tk.Button(
self.marco_botones,
text="Limpiar",
width=15,
command=self.limpiar,
state="disabled"
)
self.boton_limpiar.grid(row=0, column=1, padx=5)
self.label_resultado = tk.Label(
self.ventana,
text="Esperando fin del entrenamiento...",
font=("Arial", 13),
justify="left"
)
self.label_resultado.pack(pady=10)
def preparar_entrenamiento(self):
self.label_estado.config(text="Generando dataset de entrenamiento y validación...")
self.X_train, self.y_train = generar_dataset(120)
self.X_val, self.y_val = generar_dataset(60)
self.modelo = CNNPequena()
self.criterio = nn.CrossEntropyLoss()
self.optimizador = optim.Adam(self.modelo.parameters(), lr=0.01)
def entrenar_paso(self):
if self.epoca_actual >= self.total_epocas:
self.finalizar_entrenamiento()
return
self.modelo.train()
logits_train = self.modelo(self.X_train)
loss_train = self.criterio(logits_train, self.y_train)
self.optimizador.zero_grad()
loss_train.backward()
self.optimizador.step()
self.epoca_actual += 1
self.barra["value"] = self.epoca_actual
self.label_estado.config(
text=f"Entrenando época {self.epoca_actual} de {self.total_epocas}"
)
if self.epoca_actual % 10 == 0 or self.epoca_actual == 1:
self.modelo.eval()
with torch.no_grad():
logits_train_eval = self.modelo(self.X_train)
logits_val = self.modelo(self.X_val)
train_loss = self.criterio(logits_train_eval, self.y_train).item()
val_loss = self.criterio(logits_val, self.y_val).item()
train_acc = calcular_accuracy(logits_train_eval, self.y_train)
val_acc = calcular_accuracy(logits_val, self.y_val)
self.label_metricas.config(
text=(
f"Época: {self.epoca_actual:3d}/{self.total_epocas}\n"
f"Train loss: {train_loss:.4f}\n"
f"Val loss: {val_loss:.4f}\n"
f"Train acc: {train_acc:.3f}\n"
f"Val acc: {val_acc:.3f}"
)
)
self.ventana.after(30, self.entrenar_paso)
def finalizar_entrenamiento(self):
self.modelo.eval()
with torch.no_grad():
logits_train = self.modelo(self.X_train)
logits_val = self.modelo(self.X_val)
train_loss = self.criterio(logits_train, self.y_train).item()
val_loss = self.criterio(logits_val, self.y_val).item()
train_acc = calcular_accuracy(logits_train, self.y_train)
val_acc = calcular_accuracy(logits_val, self.y_val)
self.label_estado.config(text="Entrenamiento finalizado")
self.label_metricas.config(
text=(
f"FINAL\n"
f"Train loss: {train_loss:.4f}\n"
f"Val loss: {val_loss:.4f}\n"
f"Train acc: {train_acc:.3f}\n"
f"Val acc: {val_acc:.3f}"
)
)
self.label_dibujo.config(
text="Ahora puedes dibujar una línea y pedir la predicción"
)
self.canvas.bind("<Button-1>", self.pintar)
self.canvas.bind("<B1-Motion>", self.pintar)
self.boton_predecir.config(state="normal")
self.boton_limpiar.config(state="normal")
self.label_resultado.config(text="Modelo listo para predecir")
def pintar(self, evento):
col = evento.x // self.tamano_celda
fila = evento.y // self.tamano_celda
if 0 <= fila < self.filas and 0 <= col < self.columnas:
self.matriz[fila][col] = 1
self.canvas.itemconfig(self.rectangulos[fila][col], fill="black")
def limpiar(self):
for fila in range(self.filas):
for col in range(self.columnas):
self.matriz[fila][col] = 0
self.canvas.itemconfig(self.rectangulos[fila][col], fill="white")
self.label_resultado.config(text="Cuadrícula limpia")
def convertir_a_tensor(self):
img = torch.tensor(self.matriz, dtype=torch.float32)
img = img.unsqueeze(0).unsqueeze(0)
return img
def predecir(self):
total = sum(sum(fila) for fila in self.matriz)
if total == 0:
messagebox.showwarning("Atención", "Debes dibujar algo antes de predecir.")
return
entrada = self.convertir_a_tensor()
with torch.no_grad():
logits = self.modelo(entrada)
probs = torch.softmax(logits, dim=1)
pred = torch.argmax(probs, dim=1).item()
texto = (
f"Predicción: {self.nombres_clases[pred]}\n"
f"vertical = {probs[0][0].item():.2f}\n"
f"horizontal = {probs[0][1].item():.2f}\n"
f"oblicua = {probs[0][2].item():.2f}"
)
self.label_resultado.config(text=texto)
# ---------------------------------------------------------
# Programa principal
# ---------------------------------------------------------
if __name__ == "__main__":
ventana = tk.Tk()
app = AplicacionDibujo(ventana)
ventana.mainloop()De esta forma podemos trabajar primero con una versión compacta para comprender la CNN y, después, con una versión más visual e interactiva para experimentar dibujando entradas y observando las predicciones del modelo.
24.25 Errores comunes al empezar con CNN
- Tratar imágenes como si fueran solo vectores sin estructura.
- No entender qué representan filtros y mapas de características.
- Confundir canales con cantidad de imágenes.
- Olvidar aplanar antes de pasar a capas densas finales.
- No revisar la forma de los tensores entre capas.
24.26 Buenas prácticas
Si estás empezando con CNN, estas recomendaciones suelen ayudar mucho:
- Trabajar primero con imágenes pequeñas y ejemplos simples.
- Revisar siempre la forma de los tensores después de cada capa.
- Entender qué hace cada bloque: convolución, activación, pooling y flatten.
- No intentar memorizar arquitecturas complejas antes de comprender una CNN pequeña.
- Relacionar siempre la teoría con ejemplos concretos.
24.27 Qué debes recordar de este tema
- Las CNN están diseñadas para aprovechar la estructura espacial de las imágenes.
- Usan filtros pequeños que se aplican localmente y comparten pesos.
- Las capas convolucionales producen mapas de características.
- El pooling ayuda a resumir información y reducir tamaño espacial.
- Después de las convoluciones suele aparecer una parte densa final para clasificar.
- PyTorch implementa estas ideas con capas como
nn.Conv2dynn.MaxPool2d.
24.28 Cierre conceptual
Las redes convolucionales marcan un paso importante dentro del Deep Learning porque muestran que no todas las tareas deben resolverse con la misma arquitectura.
Comprender una CNN significa entender cómo una red puede aprovechar la forma interna de los datos y aprender patrones espaciales de manera mucho más natural que una red densa tradicional.