27. Uso de GPU para acelerar entrenamiento
27.1 Introducción
Cuando los modelos y los datasets comienzan a crecer, el tiempo de entrenamiento puede aumentar muchísimo.
En ese contexto aparece una herramienta muy importante en Deep Learning: la GPU.
En este tema vamos a estudiar qué papel cumple la GPU, por qué puede acelerar el entrenamiento y cómo usarla desde PyTorch de manera correcta.
27.2 Qué es una GPU
La sigla GPU significa Graphics Processing Unit, es decir, unidad de procesamiento gráfico.
Aunque originalmente fue pensada para tareas visuales, su arquitectura resultó especialmente útil para muchos cálculos numéricos masivos realizados en paralelo.
Por eso las GPU se volvieron una pieza fundamental en el entrenamiento de modelos de Deep Learning.
27.3 Diferencia general entre CPU y GPU
De forma simplificada, podemos pensar así:
- CPU: muy versátil, adecuada para tareas generales y variadas.
- GPU: muy fuerte en operaciones masivas y paralelas.
En Deep Learning esto es importante porque muchas operaciones sobre tensores implican enormes cantidades de multiplicaciones y sumas que se pueden paralelizar.
27.4 Por qué las GPU ayudan tanto en Deep Learning
Entrenar una red neuronal implica muchas operaciones repetitivas sobre grandes cantidades de datos y parámetros.
Por ejemplo:
- Multiplicaciones matriciales.
- Convoluciones.
- Aplicación de activaciones.
- Cálculo de gradientes.
La GPU puede ejecutar este tipo de trabajo de manera mucho más eficiente que una CPU en muchos escenarios.
27.5 No siempre la GPU será mejor en cualquier caso
Aunque la GPU suele acelerar el entrenamiento, no siempre produce una mejora grande en todos los problemas.
Si el modelo es muy pequeño o el dataset es diminuto, el costo de mover datos y coordinar el dispositivo puede hacer que la ventaja sea baja o incluso poco apreciable.
Sin embargo, en problemas medianos o grandes, la diferencia suele ser muy importante.
27.6 Qué significa “usar GPU” en PyTorch
En PyTorch, usar GPU significa mover tanto el modelo como los tensores de datos al dispositivo adecuado.
No basta con tener una GPU disponible: hay que indicarle al programa dónde vivirán los datos y el modelo.
Este punto es central, porque muchos errores al empezar vienen justamente de mezclar tensores en CPU con tensores en GPU.
27.7 El concepto de device
PyTorch usa la idea de device o dispositivo.
Un tensor o un modelo puede estar en CPU o en GPU.
Para trabajar correctamente, los tensores y el modelo que participan en una operación deben estar en dispositivos compatibles.
27.8 Cómo detectar si hay GPU disponible
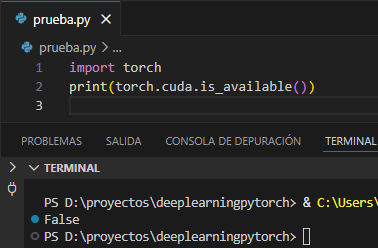
La forma usual de comprobar si PyTorch puede usar GPU es:
Esto devuelve True si CUDA está disponible y PyTorch puede usar la GPU, o False si no lo está.
Si no tienes la GPU activa en PyTorch, luego puedes probar en la consola desinstalar la versión actual e instalar una compilación con soporte CUDA:
python -m pip uninstall -y torch torchvision torchaudio
python -m pip uninstall -y torch torchvision torchaudio
python -m pip install --upgrade pip
python -m pip install --no-cache-dir --force-reinstall torch==2.7.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118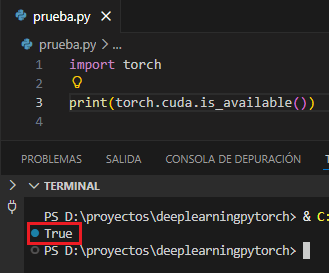
27.9 Elegir el dispositivo automáticamente
Una práctica muy común es definir un dispositivo de trabajo como este:
Así el mismo código puede funcionar tanto en una máquina con GPU como en una máquina sin GPU.
27.10 Mover tensores a un dispositivo
Una vez elegido el dispositivo, los tensores pueden moverse con .to(device).
y = y.to(device)
Esto envía los datos al mismo dispositivo que usará el modelo.
27.11 Mover el modelo a un dispositivo
El modelo también debe moverse:
Si el modelo queda en CPU pero los datos están en GPU, o al revés, aparecerán errores.
Por eso conviene pensar siempre en términos de consistencia de dispositivo.
27.12 Un error típico
Un error muy común al comenzar es este escenario:
- El modelo está en GPU.
- Los datos siguen en CPU.
Cuando se intenta hacer la propagación hacia adelante, PyTorch produce un error porque no puede mezclar esos dispositivos de forma implícita.
27.13 Regla práctica importante
Una regla muy útil es esta:
Si recuerda siempre esta idea, evitará una gran cantidad de errores habituales.
27.14 Qué es CUDA
Cuando en PyTorch hablamos de usar GPU, muchas veces aparece la palabra CUDA.
CUDA es una plataforma de computación paralela desarrollada por NVIDIA que permite usar ciertas GPU para cálculos generales.
En la práctica, cuando PyTorch usa una GPU NVIDIA, suele hacerlo a través de CUDA.
27.15 El flujo típico con GPU
Un flujo básico de trabajo suele verse así:
- Detectar si hay GPU.
- Elegir el dispositivo.
- Mover el modelo al dispositivo.
- Mover los tensores al dispositivo.
- Entrenar normalmente.
Una vez hecho esto, el resto del entrenamiento se parece bastante al que ya conocemos.
27.16 GPU y evaluación
No solo el entrenamiento puede beneficiarse de la GPU. La inferencia y la evaluación también pueden acelerarse en muchos casos.
Sin embargo, al evaluar solemos usar model.eval() y torch.no_grad(), tal como ya vimos en temas anteriores.
Es decir, la lógica general de evaluación no cambia: cambia el dispositivo donde se ejecuta.
27.17 GPU no cambia la lógica del aprendizaje
Es importante entender que usar GPU no cambia la teoría del entrenamiento.
La pérdida sigue siendo la misma, el optimizador sigue funcionando igual y backpropagation sigue calculando gradientes.
Lo que cambia es el hardware que realiza esos cálculos y, por tanto, la velocidad con que pueden ejecutarse.
27.18 Cuándo se nota más la diferencia
La diferencia entre CPU y GPU suele notarse más cuando:
- El modelo es más grande.
- El dataset es grande.
- El batch size es considerable.
- Hay muchas operaciones matriciales o convolucionales.
En ejemplos pequeños didácticos, la mejora puede existir, pero no siempre será dramática.
27.19 Qué pasa si no hay GPU disponible
Si no hay GPU disponible, PyTorch puede seguir funcionando perfectamente en CPU.
Esto es importante, porque no tener GPU no impide aprender Deep Learning.
Simplemente significa que algunos entrenamientos tardarán más.
27.20 Qué significa hacer código portable
Un buen código no debería depender rígidamente de tener una GPU.
Por eso es tan útil definir el device de manera automática y luego usarlo en el resto del programa.
Así el mismo script puede ejecutarse tanto en una notebook sencilla como en una máquina con GPU.
27.21 Qué observaremos en la aplicación final
En la aplicación final construiremos un ejemplo completo que funcione tanto en CPU como en GPU.
El objetivo será mostrar claramente:
- Cómo detectar el dispositivo.
- Cómo mover modelo y datos.
- Cómo entrenar normalmente usando ese dispositivo.
- Cómo realizar predicciones al final.
De este modo, podrá reutilizar el patrón en cualquier proyecto futuro.
27.22 Por qué el ejemplo será sencillo
No hace falta usar un modelo gigantesco para entender cómo se emplea la GPU en PyTorch.
Lo importante aquí es fijar la estructura correcta del flujo de trabajo.
Por eso usaremos un problema tabular de clasificación binaria con una red pequeña, suficiente para ver con claridad cómo se maneja el device.
27.23 Código completo para ejecutar
La siguiente aplicación permite elegir al inicio si se desea usar GPU, entrena una CNN pequeña en el dispositivo seleccionado y luego habilita una interfaz para dibujar líneas y pedir predicciones.
import time
import tkinter as tk
from tkinter import messagebox, ttk
import torch
import torch.nn as nn
import torch.optim as optim
# ---------------------------------------------------------
# Configuración general
# ---------------------------------------------------------
torch.manual_seed(24)
torch.set_printoptions(precision=2, sci_mode=False)
# ---------------------------------------------------------
# Generación de imágenes sintéticas
# ---------------------------------------------------------
def generar_imagen_vertical():
col = torch.randint(1, 7, (1,)).item()
matriz = [[0 for _ in range(8)] for _ in range(8)]
for fila in range(8):
matriz[fila][col] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_imagen_horizontal():
fila = torch.randint(1, 7, (1,)).item()
matriz = [[0 for _ in range(8)] for _ in range(8)]
for col in range(8):
matriz[fila][col] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_imagen_oblicua():
matriz = [[0 for _ in range(8)] for _ in range(8)]
tipo = torch.randint(0, 2, (1,)).item()
if tipo == 0:
for i in range(8):
matriz[i][i] = 1
else:
for i in range(8):
matriz[i][7 - i] = 1
img = torch.tensor(matriz, dtype=torch.float32)
img += 0.10 * torch.rand(8, 8)
return img.clamp(0.0, 1.0)
def generar_dataset(n_por_clase):
imagenes = []
etiquetas = []
for _ in range(n_por_clase):
imagenes.append(generar_imagen_vertical())
etiquetas.append(0)
imagenes.append(generar_imagen_horizontal())
etiquetas.append(1)
imagenes.append(generar_imagen_oblicua())
etiquetas.append(2)
X = torch.stack(imagenes).unsqueeze(1) # [N, 1, 8, 8]
y = torch.tensor(etiquetas, dtype=torch.long)
return X, y
# ---------------------------------------------------------
# Modelo
# ---------------------------------------------------------
class CNNPequena(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2)
self.fc1 = nn.Linear(16 * 2 * 2, 16)
self.fc2 = nn.Linear(16, 3)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
def calcular_accuracy(logits, y_real):
pred = torch.argmax(logits, dim=1)
return (pred == y_real).float().mean().item()
# ---------------------------------------------------------
# Aplicación Tkinter
# ---------------------------------------------------------
class AplicacionDibujo:
def __init__(self, ventana):
self.ventana = ventana
self.ventana.title("Entrenamiento y predicción de líneas con PyTorch")
self.filas = 8
self.columnas = 8
self.tamano_celda = 45
self.nombres_clases = ["vertical", "horizontal", "oblicua"]
self.total_epocas = 120
self.epoca_actual = 0
self.tiempo_inicio = None
self.tiempo_entrenamiento = 0.0
self.device = self.seleccionar_device()
self.matriz = [[0 for _ in range(self.columnas)] for _ in range(self.filas)]
self.X_train = None
self.y_train = None
self.X_val = None
self.y_val = None
self.modelo = None
self.criterio = None
self.optimizador = None
self.crear_interfaz()
self.preparar_entrenamiento()
self.ventana.after(300, self.iniciar_entrenamiento)
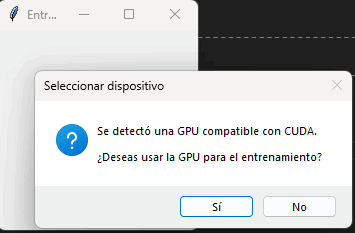
def seleccionar_device(self):
if torch.cuda.is_available():
usar_gpu = messagebox.askyesno(
"Seleccionar dispositivo",
"Se detectó una GPU compatible con CUDA.\n\n¿Deseas usar la GPU para el entrenamiento?"
)
if usar_gpu:
return torch.device("cuda")
return torch.device("cpu")
def crear_interfaz(self):
self.label_titulo = tk.Label(
self.ventana,
text="Clasificador de líneas con CNN",
font=("Arial", 18, "bold")
)
self.label_titulo.pack(pady=(10, 5))
self.label_estado = tk.Label(
self.ventana,
text=f"Dispositivo seleccionado: {self.device}",
font=("Arial", 12)
)
self.label_estado.pack(pady=5)
self.barra = ttk.Progressbar(
self.ventana,
orient="horizontal",
length=500,
mode="determinate",
maximum=self.total_epocas
)
self.barra.pack(pady=10)
self.label_metricas = tk.Label(
self.ventana,
text="Métricas aún no disponibles",
font=("Courier New", 11),
justify="left"
)
self.label_metricas.pack(pady=5)
separador = tk.Frame(self.ventana, height=2, bd=1, relief="sunken")
separador.pack(fill="x", padx=10, pady=10)
self.label_dibujo = tk.Label(
self.ventana,
text="La interfaz de dibujo se activará al finalizar el entrenamiento",
font=("Arial", 12, "italic")
)
self.label_dibujo.pack(pady=5)
self.canvas = tk.Canvas(
self.ventana,
width=self.columnas * self.tamano_celda,
height=self.filas * self.tamano_celda,
bg="white"
)
self.canvas.pack(padx=10, pady=10)
self.rectangulos = []
for fila in range(self.filas):
fila_rects = []
for col in range(self.columnas):
x1 = col * self.tamano_celda
y1 = fila * self.tamano_celda
x2 = x1 + self.tamano_celda
y2 = y1 + self.tamano_celda
rect = self.canvas.create_rectangle(
x1, y1, x2, y2,
fill="white",
outline="gray"
)
fila_rects.append(rect)
self.rectangulos.append(fila_rects)
self.canvas.bind("<Button-1>", lambda e: None)
self.canvas.bind("<B1-Motion>", lambda e: None)
self.marco_botones = tk.Frame(self.ventana)
self.marco_botones.pack(pady=10)
self.boton_predecir = tk.Button(
self.marco_botones,
text="Predecir",
width=15,
command=self.predecir,
state="disabled"
)
self.boton_predecir.grid(row=0, column=0, padx=5)
self.boton_limpiar = tk.Button(
self.marco_botones,
text="Limpiar",
width=15,
command=self.limpiar,
state="disabled"
)
self.boton_limpiar.grid(row=0, column=1, padx=5)
self.label_resultado = tk.Label(
self.ventana,
text="Esperando fin del entrenamiento...",
font=("Arial", 13),
justify="left"
)
self.label_resultado.pack(pady=10)
def preparar_entrenamiento(self):
self.label_estado.config(text=f"Generando dataset en {self.device}...")
self.X_train, self.y_train = generar_dataset(120)
self.X_val, self.y_val = generar_dataset(60)
self.X_train = self.X_train.to(self.device)
self.y_train = self.y_train.to(self.device)
self.X_val = self.X_val.to(self.device)
self.y_val = self.y_val.to(self.device)
self.modelo = CNNPequena().to(self.device)
self.criterio = nn.CrossEntropyLoss()
self.optimizador = optim.Adam(self.modelo.parameters(), lr=0.01)
def iniciar_entrenamiento(self):
self.tiempo_inicio = time.time()
self.entrenar_paso()
def entrenar_paso(self):
if self.epoca_actual >= self.total_epocas:
self.finalizar_entrenamiento()
return
self.modelo.train()
logits_train = self.modelo(self.X_train)
loss_train = self.criterio(logits_train, self.y_train)
self.optimizador.zero_grad()
loss_train.backward()
self.optimizador.step()
self.epoca_actual += 1
self.barra["value"] = self.epoca_actual
self.label_estado.config(
text=f"Entrenando en {self.device}: época {self.epoca_actual} de {self.total_epocas}"
)
if self.epoca_actual % 10 == 0 or self.epoca_actual == 1:
self.modelo.eval()
with torch.no_grad():
logits_train_eval = self.modelo(self.X_train)
logits_val = self.modelo(self.X_val)
train_loss = self.criterio(logits_train_eval, self.y_train).item()
val_loss = self.criterio(logits_val, self.y_val).item()
train_acc = calcular_accuracy(logits_train_eval, self.y_train)
val_acc = calcular_accuracy(logits_val, self.y_val)
self.label_metricas.config(
text=(
f"Época: {self.epoca_actual:3d}/{self.total_epocas}\n"
f"Train loss: {train_loss:.4f}\n"
f"Val loss: {val_loss:.4f}\n"
f"Train acc: {train_acc:.3f}\n"
f"Val acc: {val_acc:.3f}"
)
)
self.ventana.after(30, self.entrenar_paso)
def finalizar_entrenamiento(self):
self.tiempo_entrenamiento = time.time() - self.tiempo_inicio
self.modelo.eval()
with torch.no_grad():
logits_train = self.modelo(self.X_train)
logits_val = self.modelo(self.X_val)
train_loss = self.criterio(logits_train, self.y_train).item()
val_loss = self.criterio(logits_val, self.y_val).item()
train_acc = calcular_accuracy(logits_train, self.y_train)
val_acc = calcular_accuracy(logits_val, self.y_val)
self.label_estado.config(
text=(
f"Entrenamiento finalizado en {self.device}. "
f"Tiempo: {self.tiempo_entrenamiento:.2f} segundos"
)
)
self.label_metricas.config(
text=(
f"FINAL\n"
f"Train loss: {train_loss:.4f}\n"
f"Val loss: {val_loss:.4f}\n"
f"Train acc: {train_acc:.3f}\n"
f"Val acc: {val_acc:.3f}\n"
f"Segundos: {self.tiempo_entrenamiento:.2f}"
)
)
self.label_dibujo.config(
text="Ahora puedes dibujar una línea y pedir la predicción"
)
self.canvas.bind("<Button-1>", self.pintar)
self.canvas.bind("<B1-Motion>", self.pintar)
self.boton_predecir.config(state="normal")
self.boton_limpiar.config(state="normal")
self.label_resultado.config(text="Modelo listo para predecir")
def pintar(self, evento):
col = evento.x // self.tamano_celda
fila = evento.y // self.tamano_celda
if 0 <= fila < self.filas and 0 <= col < self.columnas:
self.matriz[fila][col] = 1
self.canvas.itemconfig(self.rectangulos[fila][col], fill="black")
def limpiar(self):
for fila in range(self.filas):
for col in range(self.columnas):
self.matriz[fila][col] = 0
self.canvas.itemconfig(self.rectangulos[fila][col], fill="white")
self.label_resultado.config(text="Cuadrícula limpia")
def convertir_a_tensor(self):
img = torch.tensor(self.matriz, dtype=torch.float32, device=self.device)
img = img.unsqueeze(0).unsqueeze(0)
return img
def predecir(self):
total = sum(sum(fila) for fila in self.matriz)
if total == 0:
messagebox.showwarning("Atención", "Debes dibujar algo antes de predecir.")
return
entrada = self.convertir_a_tensor()
with torch.no_grad():
logits = self.modelo(entrada)
probs = torch.softmax(logits, dim=1)
pred = torch.argmax(probs, dim=1).item()
texto = (
f"Predicción: {self.nombres_clases[pred]}\n"
f"vertical = {probs[0][0].item():.2f}\n"
f"horizontal = {probs[0][1].item():.2f}\n"
f"oblicua = {probs[0][2].item():.2f}"
)
self.label_resultado.config(text=texto)
# ---------------------------------------------------------
# Programa principal
# ---------------------------------------------------------
if __name__ == "__main__":
ventana = tk.Tk()
app = AplicacionDibujo(ventana)
ventana.mainloop()Este ejemplo muestra que el uso de GPU en PyTorch puede integrarse incluso en una aplicación visual. La lógica del modelo no cambia, pero sí debemos decidir el dispositivo, mover datos y modelo correctamente y medir el tiempo que demanda el entrenamiento.
27.24 Errores comunes al usar GPU en PyTorch
- Olvidar mover el modelo al mismo device que los datos.
- Mezclar tensores en CPU con tensores en GPU.
- Suponer que tener GPU siempre acelera cualquier ejemplo por igual.
- No comprobar si CUDA está disponible antes de usarla.
- Crear nuevos tensores durante el flujo sin moverlos al device correcto.
27.25 Buenas prácticas para estudiantes
Si estás empezando con GPU en PyTorch, estas recomendaciones suelen ayudar mucho:
- Definir un
deviceal comienzo del programa. - Mover siempre modelo y tensores a ese mismo dispositivo.
- Comprobar primero que el código funcione bien en CPU.
- Usar el mismo patrón una y otra vez hasta volverlo natural.
- Recordar que la GPU acelera el cálculo, pero no reemplaza una buena comprensión del modelo.
27.26 Qué debes recordar de este tema
- La GPU puede acelerar mucho el entrenamiento de modelos de Deep Learning.
- En PyTorch se trabaja mediante la idea de
device. - Modelo y tensores deben estar en el mismo dispositivo.
- La forma habitual es usar
torch.device("cuda" if torch.cuda.is_available() else "cpu"). - Usar GPU no cambia la teoría del entrenamiento, solo el hardware que ejecuta los cálculos.
27.27 Cierre conceptual
El uso de GPU es una parte muy importante del trabajo práctico en Deep Learning, porque permite que modelos y datasets más grandes se vuelvan manejables en tiempos razonables.
Dominar este tema significa aprender a conectar la teoría del modelo con el hardware que hace posible entrenarlo de forma eficiente.