3. Diferencias entre Machine Learning y Deep Learning
3.1 Introducción
En el mundo de la inteligencia artificial es muy común escuchar los términos Machine Learning y Deep Learning. A veces se usan como si fueran sinónimos, pero en realidad no significan exactamente lo mismo. Entender su relación y sus diferencias es fundamental para cualquier estudiante que quiera avanzar en ciencia de datos, inteligencia artificial o desarrollo de modelos predictivos.
La confusión aparece porque ambos enfoques están muy relacionados. De hecho, el Deep Learning forma parte del Machine Learning. Sin embargo, difieren en la forma en que aprenden, en el tipo de datos que manejan mejor, en la cantidad de recursos que necesitan y en los problemas donde suelen destacarse.
En este tema vamos a analizar estas diferencias de manera clara y progresiva, con ejemplos concretos y comparaciones prácticas.
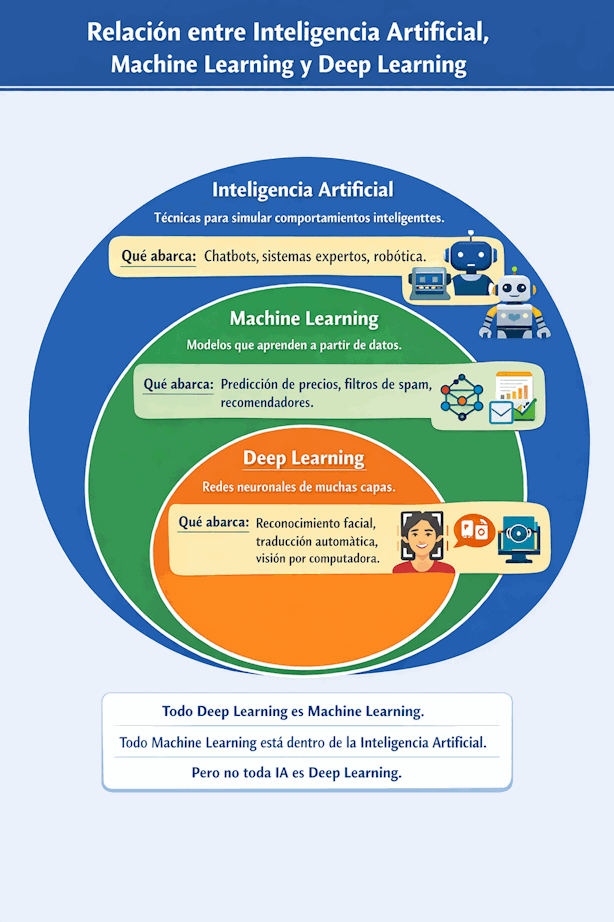
3.2 La relación correcta entre ambos conceptos
La forma más simple de entender la relación es pensar en una estructura jerárquica:
- La Inteligencia Artificial es el campo general.
- Dentro de la Inteligencia Artificial se encuentra el Machine Learning.
- Dentro del Machine Learning se encuentra el Deep Learning.
Esto significa que el Deep Learning no reemplaza al Machine Learning, sino que es una subárea especializada. Compararlos es válido, pero debemos hacerlo entendiendo que uno está contenido dentro del otro.
3.3 ¿Qué es Machine Learning?
El Machine Learning es una rama de la inteligencia artificial en la que los sistemas aprenden a partir de datos. En lugar de ser programados con reglas exactas para cada situación, los modelos descubren patrones y relaciones útiles para hacer predicciones o tomar decisiones.
Por ejemplo, si queremos predecir el precio de una casa a partir de su tamaño, su ubicación y la cantidad de habitaciones, podemos usar un modelo de Machine Learning. El sistema analiza muchos ejemplos previos y aprende la relación entre esas variables y el precio final.
Dentro del Machine Learning existen muchos algoritmos, entre ellos:
- Regresión lineal
- Regresión logística
- Árboles de decisión
- Random Forest
- Máquinas de soporte vectorial (SVM)
- K vecinos más cercanos (KNN)
- Naive Bayes
Estos métodos pueden ser muy eficaces, especialmente cuando los datos están bien estructurados en forma de tablas.
3.4 ¿Qué es Deep Learning?
El Deep Learning es una subárea del Machine Learning que utiliza redes neuronales artificiales con muchas capas. La palabra "deep" hace referencia justamente a esa profundidad: varias capas de procesamiento entre la entrada y la salida.
La idea central es que el modelo no solo aprende a dar una respuesta, sino que también aprende automáticamente las representaciones internas necesarias para llegar a esa respuesta.
Por ejemplo, si queremos reconocer objetos en imágenes, un modelo de Deep Learning puede aprender primero bordes, luego formas, después partes de objetos y finalmente el objeto completo, todo dentro de la misma red neuronal.
Este enfoque es especialmente poderoso en datos complejos como imágenes, audio, video y texto.
3.5 Primera diferencia: el tipo de modelo utilizado
La diferencia más directa entre Machine Learning y Deep Learning está en el tipo de modelos que se usan.
En Machine Learning clásico, se emplean algoritmos como árboles, regresiones, SVM o vecinos cercanos. En Deep Learning, el modelo principal es la red neuronal profunda.
| Aspecto | Machine Learning | Deep Learning |
|---|---|---|
| Modelo típico | Regresión, árbol, SVM, Random Forest, KNN. | Redes neuronales con múltiples capas. |
| Estructura | Más simple o moderada. | Más compleja y profunda. |
| Parámetros | Menor cantidad en muchos casos. | Puede tener miles, millones o más. |
3.6 Segunda diferencia: la necesidad de ingeniería de características
Una de las diferencias más importantes tiene que ver con las características o features.
En muchos problemas de Machine Learning tradicional, el especialista debe decidir qué variables son relevantes y cómo representarlas. A este proceso se lo llama ingeniería de características. Por ejemplo, si trabajamos con imágenes, podríamos extraer manualmente bordes, texturas o medidas geométricas antes de entrenar el modelo.
En Deep Learning, en cambio, la red neuronal puede aprender esas características automáticamente. Esa es una de sus grandes fortalezas.
En resumen:
- En Machine Learning clásico, muchas veces el humano diseña las características.
- En Deep Learning, el modelo aprende las características a partir de los datos.
Esta diferencia cambia completamente la forma de trabajar.
3.7 Ejemplo para entender la diferencia en características
Supongamos que queremos construir un sistema para identificar si una imagen corresponde a un perro o a un gato.
Con Machine Learning clásico, un enfoque posible sería:
- Extraer manualmente características de la imagen.
- Medir colores predominantes, bordes, texturas o formas.
- Usar esas características como entrada a un clasificador.
Con Deep Learning, en cambio, la imagen cruda puede entrar casi directamente a la red neuronal, y el modelo aprende por sí mismo qué patrones visuales son importantes.
Esto explica por qué el Deep Learning tuvo tanto éxito en visión por computadora: evitó gran parte del trabajo manual de diseño de características.
3.8 Tercera diferencia: el tipo de datos que manejan mejor
Machine Learning y Deep Learning pueden usarse en muchos problemas, pero no destacan igual en todos los tipos de datos.
El Machine Learning clásico suele funcionar muy bien en datos estructurados, es decir, tablas donde cada fila es un ejemplo y cada columna es una variable: edad, salario, cantidad de compras, temperatura, nivel educativo, etc.
El Deep Learning suele destacar más en datos no estructurados o complejos, como:
- Imágenes
- Audio
- Texto
- Video
- Secuencias largas
Esto no significa que no haya excepciones, pero como regla general es una guía muy útil.
3.9 Cuarta diferencia: la cantidad de datos necesaria
Otra diferencia clave está en la cantidad de datos que suele requerir cada enfoque.
Muchos algoritmos de Machine Learning clásico pueden ofrecer buenos resultados con conjuntos de datos relativamente pequeños o medianos, siempre que las variables sean informativas y estén bien preparadas.
El Deep Learning, en cambio, suele necesitar grandes cantidades de datos para mostrar todo su potencial. Esto ocurre porque las redes neuronales profundas tienen muchísimos parámetros y necesitan muchos ejemplos para aprender de manera robusta.
3.10 Quinta diferencia: la necesidad de poder de cómputo
El Machine Learning clásico, en muchos casos, puede entrenarse con una computadora común y en tiempos razonables. Por supuesto, depende del tamaño del problema, pero en general sus demandas computacionales suelen ser menores.
El Deep Learning, por el contrario, puede requerir un poder de cómputo mucho mayor, sobre todo cuando se trabaja con modelos grandes y grandes conjuntos de datos. Es frecuente usar GPU para acelerar el entrenamiento.
Esto también tiene impacto práctico:
- El entrenamiento puede tardar más.
- El costo de infraestructura puede ser mayor.
- Se necesita optimizar mejor el proceso.
3.11 Sexta diferencia: interpretabilidad
La interpretabilidad se refiere a qué tan fácil es entender por qué un modelo tomó una decisión.
Muchos modelos de Machine Learning clásico son más interpretables. Por ejemplo:
- Una regresión lineal permite ver cómo influye cada variable.
- Un árbol de decisión puede seguirse paso a paso.
- Incluso modelos más complejos como Random Forest pueden analizarse en cierta medida.
En Deep Learning, en cambio, esto suele ser más difícil. Una red con muchas capas y millones de parámetros funciona como una estructura interna compleja cuya lógica no siempre es fácil de explicar.
Por eso a menudo se dice que el Deep Learning es más parecido a una "caja negra" que otros modelos.
3.12 Séptima diferencia: rendimiento en problemas complejos
Aunque el Machine Learning clásico sigue siendo muy útil, el Deep Learning ha demostrado un rendimiento extraordinario en tareas muy complejas, especialmente cuando los datos son abundantes y no estructurados.
Por ejemplo, en:
- Reconocimiento de objetos en imágenes
- Reconocimiento de voz
- Traducción automática
- Generación de texto
- Procesamiento avanzado de lenguaje natural
En este tipo de problemas, el Deep Learning suele superar claramente a muchos enfoques tradicionales.
En cambio, en problemas tabulares relativamente simples, Machine Learning clásico sigue siendo una opción excelente e incluso puede ser mejor.
3.13 Octava diferencia: tiempo de desarrollo
El tiempo total de trabajo puede variar según el enfoque.
Con Machine Learning clásico, a veces se invierte mucho tiempo en preparar variables y diseñar características útiles. Sin embargo, una vez hecho eso, entrenar el modelo puede ser relativamente rápido.
Con Deep Learning, puede haber menos trabajo manual de extracción de características, pero el entrenamiento suele ser más largo, la experimentación más costosa y el ajuste del modelo más exigente.
En otras palabras:
- Machine Learning clásico: más trabajo manual en variables, menos costo de entrenamiento en muchos casos.
- Deep Learning: menos ingeniería manual de características, pero más costo computacional y más complejidad de entrenamiento.
3.14 Novena diferencia: escalabilidad y crecimiento con más datos
Muchos algoritmos clásicos mejoran con más datos, pero llega un punto en el que su rendimiento se estabiliza. Las redes neuronales profundas, en cambio, suelen aprovechar mejor cantidades masivas de información.
Esto es una de las razones por las que el Deep Learning creció tanto en la era del Big Data. Cuando se dispone de millones de ejemplos, las redes profundas pueden aprender patrones que serían muy difíciles de capturar con modelos más simples.
3.15 Comparación general resumida
| Criterio | Machine Learning | Deep Learning |
|---|---|---|
| Relación | Campo amplio dentro de la IA. | Subárea del Machine Learning. |
| Modelos | Regresión, árboles, SVM, KNN, etc. | Redes neuronales profundas. |
| Ingeniería de características | Frecuentemente necesaria. | Aprendida automáticamente en muchos casos. |
| Datos ideales | Datos estructurados y tabulares. | Imágenes, audio, texto, video y datos complejos. |
| Cantidad de datos | Puede funcionar bien con menos datos. | Suele requerir grandes volúmenes. |
| Poder de cómputo | Moderado en muchos problemas. | Alto, especialmente con GPU. |
| Interpretabilidad | Generalmente mayor. | Generalmente menor. |
| Rendimiento en tareas complejas | Bueno, pero con límites. | Muy alto en tareas complejas con datos abundantes. |
3.16 Un ejemplo práctico: predicción de abandono de clientes
Imaginemos una empresa que quiere predecir si un cliente dejará de usar su servicio. Tiene una tabla con variables como:
- Edad del cliente
- Antigüedad en la empresa
- Cantidad de reclamos
- Plan contratado
- Frecuencia de uso
Este es un caso típico donde el Machine Learning clásico puede funcionar muy bien. Un modelo como Random Forest o XGBoost podría ofrecer resultados excelentes con un costo razonable.
Usar Deep Learning aquí podría ser posible, pero no necesariamente sería la mejor elección. A veces un modelo más simple logra un rendimiento similar o incluso superior con menor complejidad.
3.17 Otro ejemplo práctico: reconocimiento de rostros
Ahora pensemos en un sistema que debe reconocer personas a partir de imágenes del rostro. Aquí el problema cambia completamente. Los datos ya no son filas simples de una tabla, sino miles o millones de píxeles.
En este tipo de tarea, el Deep Learning suele ser claramente superior. Las redes convolucionales pueden aprender patrones visuales complejos de manera automática, algo muy difícil de lograr con Machine Learning clásico sin un enorme trabajo manual previo.
Este ejemplo ayuda a entender una idea central: la elección del enfoque depende mucho del tipo de problema y del tipo de datos.
3.18 ¿Significa esto que el Deep Learning es siempre mejor?
No. Ese es un error muy común.
El Deep Learning es extremadamente poderoso, pero no siempre es la mejor herramienta. Hay muchas situaciones donde el Machine Learning clásico es más conveniente:
- Cuando hay pocos datos.
- Cuando los datos son tabulares y bien estructurados.
- Cuando se necesita una explicación clara del modelo.
- Cuando el hardware disponible es limitado.
- Cuando se busca una solución más simple y rápida de implementar.
Elegir un modelo más complejo solo porque está de moda no es una buena decisión técnica.
3.19 ¿Cuándo conviene pensar en Deep Learning?
El Deep Learning suele ser una opción especialmente atractiva en situaciones como estas:
- Trabajas con imágenes, audio, texto o video.
- Dispones de una gran cantidad de datos.
- Tienes acceso a GPU u otros recursos de cómputo.
- La tarea es compleja y los métodos tradicionales se quedan cortos.
- Buscas el mejor rendimiento posible aunque el modelo sea más difícil de interpretar.
3.20 ¿Cuándo conviene pensar en Machine Learning clásico?
El Machine Learning clásico suele ser una excelente opción cuando:
- Los datos están organizados en tablas.
- La cantidad de datos no es enorme.
- Necesitas resultados rápidos y robustos.
- La interpretabilidad importa mucho.
- Quieres una línea base sólida antes de probar modelos más complejos.
De hecho, en proyectos reales es muy común comenzar con modelos clásicos y usar Deep Learning solo cuando realmente aporta valor.
3.21 El papel del especialista humano en cada enfoque
En Machine Learning clásico, el papel del especialista suele centrarse mucho en:
- Seleccionar variables.
- Limpiar datos.
- Crear características útiles.
- Elegir el algoritmo adecuado.
En Deep Learning, muchas veces el esfuerzo se desplaza hacia:
- Diseñar la arquitectura de la red.
- Preparar grandes volúmenes de datos.
- Ajustar hiperparámetros.
- Controlar el entrenamiento y evitar sobreajuste.
En ambos casos sigue siendo fundamental el criterio humano. Ningún modelo "aprende solo" en el sentido absoluto del término.
3.22 ¿Qué papel tiene PyTorch en esta diferencia?
PyTorch es una biblioteca orientada principalmente al desarrollo de modelos de Deep Learning. Aunque puede usarse para operaciones numéricas generales, su gran fortaleza está en:
- Construcción de redes neuronales.
- Cálculo automático de gradientes.
- Entrenamiento eficiente en GPU.
- Experimentación flexible con arquitecturas profundas.
En cambio, para Machine Learning clásico es muy común utilizar bibliotecas como Scikit-learn. Esto también refleja la diferencia entre ambos mundos: herramientas distintas para necesidades distintas.
3.23 Qué debe entender un estudiante al comparar ambos enfoques
Lo más importante es no caer en simplificaciones erróneas. No se trata de que uno sea "viejo" y el otro "nuevo", ni de que uno sea "malo" y el otro "bueno". Se trata de herramientas con fortalezas diferentes.
Un buen profesional no elige una técnica por moda, sino por adecuación al problema. Para eso necesita comprender:
- Qué datos tiene.
- Cuántos datos tiene.
- Qué recursos computacionales posee.
- Qué nivel de precisión necesita.
- Qué nivel de interpretación requiere.
3.24 Qué debes recordar de este tema
- El Deep Learning es una subárea del Machine Learning.
- Machine Learning clásico usa muchos tipos de modelos; Deep Learning se basa en redes neuronales profundas.
- El Machine Learning suele funcionar muy bien en datos tabulares y estructurados.
- El Deep Learning sobresale especialmente en imágenes, audio, texto y otros datos complejos.
- El Deep Learning suele requerir más datos y más poder de cómputo.
- El Machine Learning clásico suele ser más interpretable.
- No siempre el Deep Learning es la mejor opción.
- La elección correcta depende del problema, de los datos y de los recursos disponibles.
3.25 Conclusión
Machine Learning y Deep Learning están profundamente conectados, pero no son lo mismo. El Machine Learning ofrece un conjunto amplio de herramientas muy eficaces para aprender a partir de datos. El Deep Learning, por su parte, representa una forma especializada de aprendizaje basada en redes neuronales profundas, especialmente poderosa en tareas complejas y datos no estructurados.
La mejor forma de avanzar es comprender ambos enfoques y saber en qué contexto conviene cada uno. En este curso nos enfocaremos en Deep Learning con PyTorch, pero siempre teniendo presente que forma parte de un panorama más amplio dentro de la inteligencia artificial.
En el próximo tema seguiremos construyendo esa base conceptual al estudiar los conceptos fundamentales de las redes neuronales.