4. Conceptos fundamentales de redes neuronales
4.1 Introducción
Para trabajar con Deep Learning no alcanza con saber que existen redes neuronales. Es necesario entender sus piezas básicas, cómo se conectan y cómo procesan la información. Estos conceptos fundamentales son el idioma base del curso: aparecerán una y otra vez cuando construyamos modelos con PyTorch.
Una red neuronal puede parecer algo complejo a primera vista, pero en realidad está formada por ideas relativamente simples que, combinadas en gran cantidad, permiten resolver tareas muy sofisticadas.
En este tema veremos esas ideas una por una, con un enfoque claro y pensado para estudiantes que están comenzando.
4.2 ¿Qué es una red neuronal artificial?
Una red neuronal artificial es un modelo matemático inspirado de manera muy simplificada en el funcionamiento del cerebro. Está compuesta por muchas unidades pequeñas llamadas neuronas artificiales, organizadas en capas y conectadas entre sí.
Su objetivo es recibir datos de entrada, transformarlos internamente y producir una salida útil, como una clasificación, una predicción numérica o una decisión.
Por ejemplo, una red neuronal puede recibir información sobre una vivienda y predecir su precio. También puede recibir una imagen y decidir si contiene un perro, un gato o un automóvil.
4.3 La neurona artificial: la unidad básica
La neurona artificial es el bloque más simple dentro de una red neuronal. Su funcionamiento puede resumirse en tres pasos:
- Recibe uno o varios valores de entrada.
- Combina esos valores usando pesos y un sesgo.
- Aplica una función para producir una salida.
Es decir, la neurona no solo recibe información, sino que la transforma. Esa transformación es lo que permite que la red aprenda patrones.
4.4 Entradas: la información que recibe la red
Las entradas son los datos con los que trabaja la red neuronal. Pueden ser números que representan distintas características del problema.
Por ejemplo, si queremos predecir el precio de una casa, algunas entradas podrían ser:
- Superficie en metros cuadrados
- Cantidad de habitaciones
- Antigüedad de la vivienda
- Ubicación
Si trabajamos con imágenes, las entradas pueden ser los valores numéricos de los píxeles. Si trabajamos con audio, pueden ser muestras de señal. Si trabajamos con texto, pueden ser representaciones numéricas de palabras o fragmentos del lenguaje.
En Deep Learning, todo termina convirtiéndose en números.
4.5 Pesos: la importancia de cada entrada
No todas las entradas tienen la misma relevancia. Para eso existen los pesos. Cada entrada de una neurona se multiplica por un peso, y ese peso indica cuánto debe influir esa entrada en el resultado final.
Si un peso es grande, significa que la entrada asociada tiene mucha influencia. Si es pequeño, su influencia será menor. Si el peso es negativo, puede hacer que esa entrada empuje el resultado en dirección opuesta.
Por ejemplo, en un problema de aprobación de crédito, el nivel de ingreso puede tener un peso positivo alto, mientras que la cantidad de deudas puede tener un efecto negativo.
Aprender en una red neuronal significa, en gran parte, encontrar buenos valores para estos pesos.
4.6 Sesgo o bias: el ajuste adicional
Además de los pesos, una neurona suele incluir un valor llamado bias o sesgo. Este valor se suma al resultado de la combinación ponderada de entradas.
¿Para qué sirve? Sirve para dar flexibilidad al modelo. Permite desplazar la respuesta de la neurona y evitar que todo dependa exclusivamente de que las entradas sean grandes o pequeñas.
Una forma intuitiva de pensarlo es esta: los pesos controlan cuánto influye cada entrada, mientras que el bias permite ajustar el punto a partir del cual la neurona se activa más o menos.
4.7 Suma ponderada: la combinación inicial
Antes de producir una salida, la neurona realiza una combinación matemática de sus entradas. Multiplica cada entrada por su peso correspondiente, suma todos esos productos y luego agrega el bias.
De manera conceptual:
Esta suma ponderada es una parte fundamental de casi todas las redes neuronales. A partir de ella, la neurona decide qué salida producir.
4.8 Función de activación: decidir la respuesta
Después de calcular la suma ponderada, la neurona suele aplicar una función de activación. Esta función transforma el valor obtenido y define la salida final de la neurona.
Las funciones de activación son esenciales porque introducen no linealidad. Sin ellas, una red con muchas capas se comportaría en la práctica como una transformación lineal más simple.
Más adelante estudiaremos funciones de activación concretas como ReLU, Sigmoid y Tanh. Por ahora, lo importante es entender su papel: permiten que la red aprenda relaciones complejas y no solo proporciones simples.
4.9 Salida: el resultado de la neurona o de la red
La salida de una neurona puede convertirse en entrada para otras neuronas. Cuando hablamos de la red completa, la salida final depende del problema que queremos resolver.
Algunos ejemplos:
- Un número: si predecimos temperatura o precio.
- Una probabilidad: si queremos saber la chance de que un correo sea spam.
- Una clase: si queremos clasificar una imagen entre varias categorías.
La red completa transforma datos de entrada en una salida final pasando por múltiples neuronas y capas intermedias.
4.10 Capas: cómo se organiza la red
Las neuronas no están sueltas. Se organizan en capas. En una red neuronal típica encontramos tres tipos principales de capas:
- Capa de entrada: recibe los datos iniciales.
- Capas ocultas: procesan la información internamente.
- Capa de salida: produce la respuesta final.
Las capas ocultas se llaman así porque no están directamente visibles para el usuario: forman parte del procesamiento interno del modelo.
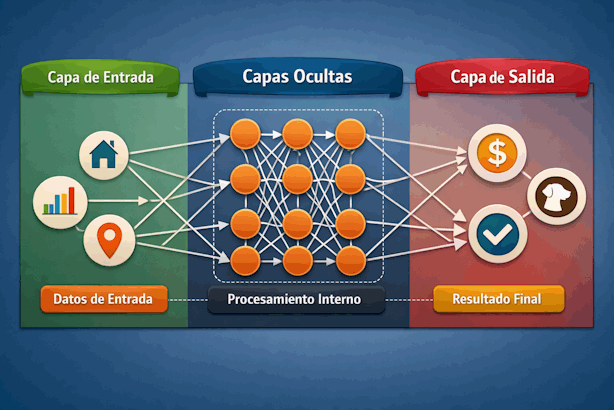
4.11 Capa de entrada
La capa de entrada es el punto de contacto entre los datos y la red. No suele realizar cálculos complejos por sí misma; su función principal es presentar los valores iniciales al resto del modelo.
Si un problema tiene 10 variables de entrada, la capa de entrada tendrá normalmente 10 nodos. Si una imagen tiene muchos píxeles, esos píxeles se convierten en los datos de entrada del sistema.
4.12 Capas ocultas
Las capas ocultas son el corazón de la red neuronal. En ellas se realizan las transformaciones que permiten extraer patrones, combinar información y construir representaciones más útiles.
Cuantas más capas ocultas tenga una red, más "profunda" será. De ahí surge el término Deep Learning.
Por ejemplo, en una red para reconocimiento de imágenes:
- Una capa puede detectar bordes.
- Otra capa puede detectar texturas.
- Otra puede reconocer partes de objetos.
- Las últimas pueden identificar el objeto completo.
4.13 Capa de salida
La capa de salida entrega el resultado final del modelo. Su forma depende del tipo de tarea:
- En regresión: puede tener una sola neurona que devuelve un número (por ejemplo, predecir el precio de una vivienda).
- En clasificación binaria: puede tener una neurona que devuelve una probabilidad (por ejemplo, determinar si un correo es spam o no spam).
- En clasificación multiclase: puede tener varias neuronas, una por clase (por ejemplo, identificar si una imagen corresponde a un gato, un perro o un pájaro).
La arquitectura de la capa de salida debe estar alineada con el problema que queremos resolver.
4.14 Conexiones entre neuronas
Las neuronas de una capa suelen estar conectadas con las de la capa siguiente. Cada conexión tiene un peso asociado. Esto significa que la salida de una neurona no pasa a la siguiente "tal cual", sino modulada por ese peso.
Las conexiones permiten que la información fluya por la red y que diferentes neuronas colaboren en la construcción de una respuesta.
En redes totalmente conectadas, cada neurona de una capa se conecta con todas las de la siguiente. En otras arquitecturas, como CNN o RNN, las conexiones siguen patrones más especializados.
4.15 Arquitectura de una red neuronal
La palabra arquitectura se refiere a la forma general de la red: cuántas capas tiene, cuántas neuronas hay en cada una, cómo están conectadas y qué funciones de activación utiliza.
Elegir una arquitectura adecuada es una parte importante del diseño de un modelo. No existe una arquitectura universalmente mejor para todos los problemas.
Algunos ejemplos de decisiones de arquitectura son:
- Número de capas ocultas
- Cantidad de neuronas por capa
- Tipo de activación
- Tipo de capa: densa, convolucional, recurrente, etc.
4.16 Parámetros y aprendizaje
Los parámetros de una red son los valores que el modelo aprende durante el entrenamiento. Principalmente, estos parámetros son los pesos y los bias.
Cuando entrenamos una red neuronal, lo que buscamos es ajustar esos parámetros para que la salida del modelo se acerque lo más posible a la respuesta correcta.
Cuantos más parámetros tiene una red, mayor puede ser su capacidad para aprender patrones complejos. Pero también mayor puede ser el riesgo de sobreajuste y mayor el costo computacional.
4.17 Hiperparámetros: decisiones definidas por el usuario
Es importante distinguir entre parámetros e hiperparámetros.
- Los parámetros los aprende el modelo durante el entrenamiento.
- Los hiperparámetros los define el usuario antes o durante el proceso de entrenamiento.
Ejemplos de hiperparámetros:
- Tasa de aprendizaje
- Número de capas
- Cantidad de neuronas por capa
- Tamaño del batch
- Número de épocas
Más adelante veremos estos conceptos en detalle, pero conviene diferenciarlos desde ahora.
4.18 Flujo de información dentro de la red
Cuando una red procesa un ejemplo, la información avanza desde la entrada hacia la salida. Este recorrido se llama propagación hacia adelante o forward propagation.
En ese proceso:
- La red recibe las entradas.
- Cada capa transforma la información.
- La salida final produce una predicción.
Luego, durante el entrenamiento, esa predicción se compara con la respuesta correcta y se corrigen los parámetros mediante otro proceso que estudiaremos más adelante: el backpropagation.
4.19 No linealidad: por qué las redes pueden aprender cosas complejas
Una idea central en redes neuronales es la no linealidad. Si todas las transformaciones de una red fueran lineales, el modelo tendría una capacidad limitada y no podría capturar relaciones complejas entre variables.
Las funciones de activación permiten introducir esa no linealidad. Gracias a ellas, la red puede modelar comportamientos mucho más ricos: curvas complejas, fronteras de decisión irregulares y patrones difíciles de describir con una fórmula simple.
Esto es parte de lo que hace tan poderoso al Deep Learning.
4.20 Representaciones internas
Una red neuronal no solo produce una salida. También construye representaciones internas de los datos. Es decir, a medida que la información pasa por las capas, cambia de forma y se vuelve más útil para la tarea.
Por ejemplo, una imagen inicialmente es solo una matriz de píxeles. Pero después de varias capas, la red puede haber transformado esa imagen en una representación interna que resalta bordes, formas, texturas y combinaciones visuales importantes.
Este aprendizaje de representaciones es una de las mayores diferencias entre las redes neuronales profundas y muchos métodos clásicos.
4.21 Un ejemplo sencillo paso a paso
Supongamos una red pequeña que recibe dos entradas:
- Horas de estudio
- Cantidad de ejercicios resueltos
Y quiere predecir si un estudiante aprobará un examen.
El proceso conceptual sería:
- La red recibe ambos valores.
- Cada valor se multiplica por un peso.
- Se suma un bias.
- Se aplica una función de activación.
- Se genera una salida, por ejemplo una probabilidad de aprobación.
Si la predicción es mala, durante el entrenamiento se ajustan los pesos para mejorarla.
4.22 Capacidad del modelo
La capacidad de una red neuronal se refiere a su habilidad para aprender patrones y relaciones en los datos. Una red muy pequeña puede no tener capacidad suficiente para resolver un problema complejo. Una red demasiado grande puede aprender demasiado bien los datos de entrenamiento y no generalizar bien.
Por eso, diseñar una red implica buscar un equilibrio. Más adelante esto se relacionará con conceptos como subajuste, sobreajuste y regularización.
4.23 Generalización
Una red neuronal no debe limitarse a memorizar ejemplos. Su verdadero objetivo es generalizar, es decir, funcionar bien con datos nuevos que no vio durante el entrenamiento.
Si una red aprende solo los ejemplos exactos del entrenamiento, pero falla ante nuevos casos, entonces no está resolviendo realmente el problema.
La generalización es uno de los objetivos centrales del aprendizaje automático y será una preocupación constante en el entrenamiento de modelos.
4.24 Entrenamiento e inferencia
Conviene diferenciar dos momentos en la vida de una red neuronal:
- Entrenamiento: la red aprende ajustando sus parámetros.
- Inferencia: la red ya entrenada se usa para hacer predicciones sobre nuevos datos.
Durante el entrenamiento, el modelo necesita ejemplos y respuestas correctas. Durante la inferencia, solo necesita nuevas entradas para producir resultados.
4.25 Redes pequeñas y redes profundas
No todas las redes neuronales son profundas. Una red sencilla puede tener una sola capa oculta. Una red profunda tiene varias capas ocultas.
La ventaja de la profundidad es que permite aprender representaciones jerárquicas. Sin embargo, también aumenta la complejidad del entrenamiento y la necesidad de recursos.
Por eso el Deep Learning no es solo "usar redes neuronales", sino trabajar con redes suficientemente complejas y profundas para capturar patrones avanzados.
4.26 Resumen conceptual de los componentes básicos
| Concepto | Qué significa | Función en la red |
|---|---|---|
| Entrada | Dato que recibe el modelo. | Proporciona la información inicial. |
| Peso | Valor que mide la importancia de una conexión. | Modula la influencia de cada entrada. |
| Bias | Ajuste adicional sumado a la combinación. | Da flexibilidad al modelo. |
| Activación | Función aplicada al resultado intermedio. | Introduce no linealidad. |
| Capa | Conjunto de neuronas. | Organiza el procesamiento. |
| Salida | Respuesta final del modelo. | Entrega la predicción o clasificación. |
4.27 Qué debes recordar de este tema
- Una red neuronal está formada por neuronas artificiales organizadas en capas.
- Cada neurona recibe entradas, aplica pesos y bias, y produce una salida.
- Los pesos indican la importancia de cada entrada.
- El bias agrega flexibilidad al comportamiento de la neurona.
- Las funciones de activación permiten aprender relaciones no lineales.
- Las capas ocultas transforman la información de manera progresiva.
- Aprender significa ajustar parámetros para mejorar las predicciones.
- El objetivo final no es memorizar, sino generalizar.
4.28 Conclusión
Los conceptos fundamentales de redes neuronales son la base sobre la que se construye todo el Deep Learning. Una vez que se entienden entradas, pesos, bias, activaciones, capas y flujo de información, el funcionamiento general de una red deja de parecer misterioso y empieza a volverse lógico.
Este tema es especialmente importante porque prepara el terreno para lo que viene. En los próximos capítulos iremos profundizando en cada componente, comenzando por las neuronas artificiales y el perceptrón, que son el punto de partida histórico y conceptual de las redes neuronales modernas.