5. Neuronas artificiales y perceptrón
5.1 Introducción
En el tema anterior vimos que una red neuronal está formada por unidades básicas llamadas neuronas artificiales. En este tema daremos un paso más: estudiaremos con detalle qué es una neurona artificial y cómo el perceptrón se convirtió en uno de los primeros modelos capaces de aprender a partir de ejemplos.
Este tema es muy importante porque el perceptrón, aunque hoy resulte simple, representa el punto de partida conceptual de gran parte del Deep Learning moderno. Entenderlo ayuda a comprender cómo una red neuronal toma decisiones y cómo aprende a clasificar datos.
5.2 ¿Qué es una neurona artificial?
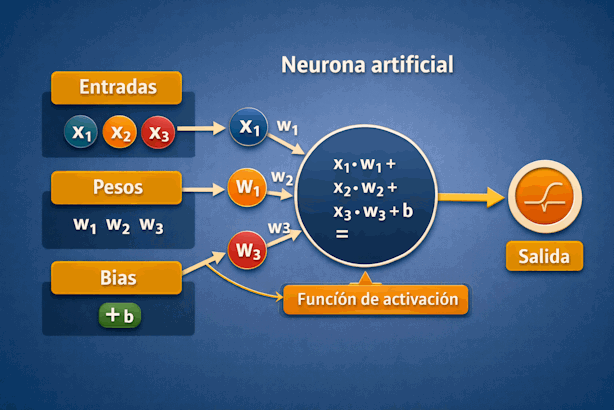
Una neurona artificial es una unidad matemática que recibe varias entradas numéricas, les asigna una importancia, las combina y genera una salida. Se inspira de manera simplificada en la neurona biológica, pero funciona como un mecanismo matemático y computacional.
La idea básica es la siguiente:
- La neurona recibe valores de entrada.
- A cada valor se le asigna un peso.
- Se calcula una suma ponderada.
- Se agrega un sesgo o bias.
- Se aplica una regla de activación.
- Se obtiene una salida.
Esto puede parecer abstracto, pero en realidad es una forma organizada de tomar una decisión basada en varios factores.
5.3 Inspiración biológica: similitud y diferencia
En el cerebro humano, una neurona recibe señales de otras neuronas a través de sus conexiones. Si la señal total supera cierto umbral, la neurona se activa y transmite una respuesta.
La neurona artificial sigue una idea parecida:
- Recibe varias señales de entrada.
- Evalúa la intensidad total de esas señales.
- Decide si responde o en qué magnitud responde.
Sin embargo, no debemos pensar que una neurona artificial reproduce el cerebro de forma realista. Es solo una simplificación útil para construir modelos de aprendizaje.
5.4 Componentes de una neurona artificial
Los componentes más importantes de una neurona artificial son:
- Entradas: los datos que recibe.
- Pesos: la importancia de cada entrada.
- Bias: un ajuste adicional.
- Función de activación: la regla que produce la salida final.
Estos elementos aparecen una y otra vez en redes neuronales más complejas. El perceptrón es una de las formas más simples de reunirlos en un modelo completo.
5.5 Entradas: los datos con los que decide la neurona
Las entradas representan la información disponible para tomar una decisión. Cada entrada es una característica del problema.
Por ejemplo, si una neurona quiere decidir si una persona debería recibir un crédito, algunas entradas podrían ser:
- Ingreso mensual
- Edad
- Historial de pagos
- Nivel de endeudamiento
La neurona no interpreta estas variables como conceptos humanos, sino como números que debe combinar matemáticamente.
5.6 Pesos: cuánto importa cada entrada
Los pesos indican la importancia relativa de cada entrada. Si una entrada tiene un peso grande, influye mucho en la decisión de la neurona. Si tiene un peso pequeño, su efecto es menor.
Por ejemplo, en un modelo para aprobar créditos, el ingreso mensual podría tener un peso positivo importante, mientras que una deuda alta podría tener un peso negativo.
Los pesos son fundamentales porque permiten que la neurona aprenda qué factores deben empujar la decisión hacia un lado o hacia el otro.
5.7 Bias: el ajuste que desplaza la decisión
El bias, también llamado sesgo, es un valor adicional que se suma al resultado antes de aplicar la activación. Sirve para darle más flexibilidad al modelo.
Sin bias, la neurona estaría demasiado limitada y muchas veces no podría ajustar correctamente su comportamiento. El bias permite desplazar el umbral de decisión.
Una manera intuitiva de verlo es esta:
- Los pesos dicen cuánto influye cada entrada.
- El bias permite mover la frontera de decisión.
5.8 Suma ponderada: el cálculo central
La neurona combina sus entradas multiplicándolas por sus pesos y sumándolas. Luego agrega el bias. Ese resultado es el valor central sobre el que se tomará la decisión.
Donde:
xrepresenta las entradas.wrepresenta los pesos.brepresenta el bias.zes el resultado previo a la activación.
Este cálculo es la base de casi todas las redes neuronales modernas.
5.9 La idea de umbral
En los primeros modelos, la neurona se comportaba como una unidad que comparaba el valor calculado contra un umbral. Si el valor superaba el umbral, la salida era 1. Si no lo superaba, la salida era 0.
Esta lógica binaria es clave para entender el perceptrón. El modelo debía decidir entre dos posibilidades, como si dijera:
- Sí o no
- Clase A o clase B
- Activa o no activa
Aunque las redes modernas usan funciones más sofisticadas, esta idea de umbral es un buen punto de partida para entender cómo una neurona toma decisiones.
5.10 ¿Qué es el perceptrón?
El perceptrón es uno de los modelos más antiguos e importantes en la historia de las redes neuronales. Fue propuesto por Frank Rosenblatt en 1957 y puede considerarse una neurona artificial capaz de aprender una regla de clasificación binaria.
Su funcionamiento es relativamente simple:
- Recibe varias entradas numéricas.
- Calcula una combinación ponderada.
- Aplica una función escalón o umbral.
- Devuelve una salida binaria.
Es decir, el perceptrón clasifica un ejemplo en una de dos categorías posibles.
5.11 ¿Para qué sirve el perceptrón?
El perceptrón sirve para problemas simples de clasificación binaria, donde la salida tiene dos valores posibles. Por ejemplo:
- Spam o no spam
- Aprobado o desaprobado
- Compra o no compra
- Perro o no perro
Si el problema puede separarse adecuadamente con una regla lineal, el perceptrón puede aprender esa regla.
5.12 La función escalón
El perceptrón clásico utiliza una función de activación muy simple llamada función escalón. Esta función devuelve un valor binario:
- Si el valor calculado es mayor que cierto umbral, la salida es 1.
- Si no lo supera, la salida es 0.
Esto convierte al perceptrón en una herramienta de decisión binaria.
Si z < 0, salida = 0
Más adelante veremos que las redes modernas suelen reemplazar esta función por otras más útiles para entrenar modelos complejos.
5.13 Un ejemplo intuitivo del perceptrón
Supongamos que queremos decidir si un estudiante aprueba o no un examen según dos variables:
- Horas de estudio
- Cantidad de ejercicios resueltos
El perceptrón recibe esos dos valores, les aplica pesos, suma un bias y produce una salida:
1si predice que aprueba0si predice que no aprueba
En este caso, el modelo está construyendo una regla matemática para separar dos grupos: aprobados y desaprobados.
5.14 El perceptrón como frontera de decisión
Desde un punto de vista geométrico, el perceptrón intenta encontrar una frontera de decisión lineal que separe las dos clases.
En dos dimensiones, esa frontera puede imaginarse como una línea. En tres dimensiones, sería un plano. En dimensiones mayores, hablamos de un hiperplano.
La idea es esta: los ejemplos de una clase deben quedar de un lado de la frontera, y los de la otra clase, del otro lado.
Si eso es posible, entonces el perceptrón puede resolver el problema.
5.15 ¿Cómo aprende el perceptrón?
El perceptrón aprende ajustando sus pesos y su bias a partir de ejemplos etiquetados. Esto significa que durante el entrenamiento se le muestran entradas junto con la respuesta correcta.
El proceso básico es:
- Recibir un ejemplo de entrada.
- Calcular la salida predicha.
- Compararla con la salida correcta.
- Si hay error, ajustar pesos y bias.
- Repetir con muchos ejemplos.
Con suficientes iteraciones, el perceptrón puede aprender una separación correcta si el problema es linealmente separable.
5.16 Regla de aprendizaje del perceptrón
La idea central de la regla de aprendizaje es corregir los pesos cuando el modelo se equivoca.
Si el perceptrón predice mal, los pesos se actualizan para empujar la próxima predicción en la dirección correcta. De forma intuitiva:
- Si debía haber activado y no lo hizo, se refuerzan ciertas conexiones.
- Si activó cuando no debía, se debilitan ciertas conexiones.
Esta fue una de las primeras formas prácticas de hacer que un modelo ajustara internamente su comportamiento a partir de errores.
5.17 Ventajas del perceptrón
- Es simple de entender: ayuda a comprender la lógica básica de una neurona artificial.
- Aprende automáticamente: no necesita reglas programadas a mano.
- Sirve como base conceptual: muchas ideas del Deep Learning nacen aquí.
- Introduce la clasificación binaria: un problema muy común en Machine Learning.
5.18 Limitaciones del perceptrón
Aunque fue un avance histórico muy importante, el perceptrón tiene limitaciones claras:
- Solo resuelve problemas de clasificación binaria simples.
- Solo funciona bien cuando las clases pueden separarse linealmente.
- No puede resolver problemas más complejos con una sola capa.
La limitación más famosa está relacionada con la función lógica XOR, que no puede ser resuelta por un perceptrón simple.
5.19 El problema XOR
La compuerta lógica XOR devuelve 1 cuando las entradas son diferentes y 0 cuando son iguales. Si representamos sus cuatro casos en el plano, los puntos que valen 1 son (0,1) y (1,0), mientras que los que valen 0 son (0,0) y (1,1).
| Entrada 1 | Entrada 2 | Salida XOR | Punto en el plano |
|---|---|---|---|
| 0 | 0 | 0 | (0,0) |
| 0 | 1 | 1 | (0,1) |
| 1 | 0 | 1 | (1,0) |
| 1 | 1 | 0 | (1,1) |
El problema es que los puntos con salida 1 quedan en esquinas opuestas, y los puntos con salida 0 también. Por eso no existe una sola recta que deje todos los 1 de un lado y todos los 0 del otro. Siempre quedará al menos un punto mal separado.
Esto significa que un perceptrón simple no puede resolverlo, porque solo sabe construir una única frontera lineal.
Este hecho fue clave en la historia de las redes neuronales, ya que mostró que un solo perceptrón era insuficiente para ciertos problemas aparentemente sencillos.
5.20 ¿Cómo se superó esa limitación?
La solución fue conectar varias neuronas y organizar modelos con múltiples capas. De esta manera surgieron redes neuronales más potentes, capaces de aprender relaciones no lineales y resolver problemas que un perceptrón simple no podía manejar.
Es decir, el perceptrón no fue el final del camino, sino el comienzo. Su principal valor histórico fue mostrar que una unidad matemática podía aprender. Luego, la evolución hacia redes multicapa abrió la puerta al Deep Learning.
5.21 Relación entre neurona artificial y perceptrón
El perceptrón puede entenderse como una implementación concreta de una neurona artificial para clasificación binaria. No toda neurona artificial moderna es un perceptrón en sentido estricto, pero el perceptrón es uno de los primeros modelos formales de neurona artificial.
En otras palabras:
- La neurona artificial es una idea general.
- El perceptrón es un modelo específico basado en esa idea.
5.22 Del perceptrón a las redes neuronales modernas
Las redes neuronales modernas mantienen la lógica básica del perceptrón:
- Entradas
- Pesos
- Bias
- Activación
- Aprendizaje a partir de errores
La gran diferencia es que hoy trabajamos con muchas capas, millones de parámetros, funciones de activación más adecuadas y algoritmos de entrenamiento más sofisticados.
Aun así, el corazón conceptual sigue siendo el mismo: una combinación matemática de señales que permite aprender patrones.
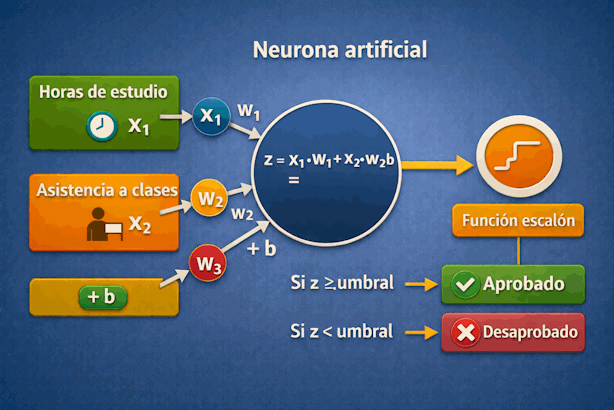
5.23 Ejemplo conceptual con dos entradas
Imaginemos una neurona artificial con dos entradas:
x1: horas de estudiox2: asistencia a clases
La neurona tiene dos pesos:
w1para las horas de estudiow2para la asistencia
Y además un bias b.
Calcula:
Luego aplica una función escalón:
- Si
zsupera el umbral, predice aprobado. - Si no lo supera, predice desaprobado.
Este esquema, aunque simple, ya contiene las ideas esenciales del aprendizaje neuronal.
5.24 Comparación entre perceptrón simple y red neuronal multicapa
| Aspecto | Perceptrón simple | Red neuronal multicapa |
|---|---|---|
| Número de capas | Una sola capa de decisión. | Varias capas ocultas y salida. |
| Tipo de problema | Clasificación binaria simple. | Problemas más complejos y no lineales. |
| Capacidad | Limitada. | Mucho mayor. |
| Frontera de decisión | Lineal. | Puede ser no lineal. |
| Uso histórico | Base inicial del aprendizaje neuronal. | Base del Deep Learning moderno. |
5.25 ¿Por qué sigue siendo importante estudiar el perceptrón?
Aunque hoy trabajamos con arquitecturas mucho más potentes, estudiar el perceptrón sigue siendo muy útil porque:
- Permite comprender la lógica elemental de una neurona artificial.
- Ayuda a entender el origen histórico de las redes neuronales.
- Introduce la idea de aprendizaje a partir de ejemplos.
- Muestra claramente las limitaciones que impulsaron la evolución hacia modelos más profundos.
En educación, el perceptrón cumple un papel parecido al de un modelo básico en física o en matemática: no representa toda la complejidad del mundo real, pero permite entender la idea central.
5.26 Qué debes recordar de este tema
- Una neurona artificial recibe entradas, aplica pesos y bias, y produce una salida.
- El perceptrón es uno de los primeros modelos de neurona artificial con aprendizaje.
- El perceptrón sirve para clasificación binaria simple.
- Su decisión se basa en una combinación ponderada y una función escalón.
- Puede aprender ajustando pesos a partir de errores.
- Su gran limitación es que solo resuelve problemas linealmente separables.
- El problema XOR mostró que un perceptrón simple no era suficiente.
- Las redes neuronales modernas nacen al extender esta idea hacia múltiples capas.
5.27 Conclusión
Las neuronas artificiales y el perceptrón representan el punto de partida conceptual de las redes neuronales. Aunque hoy los modelos sean mucho más sofisticados, la lógica esencial sigue siendo la misma: combinar información, asignarle importancia y producir una salida útil.
Entender el perceptrón es entender la semilla de todo el Deep Learning. A partir de aquí, la siguiente pieza fundamental será estudiar las funciones de activación, ya que ellas permiten que las redes neuronales superen la simple linealidad y aprendan relaciones mucho más complejas.