99 - Acceso a Internet mediante el paquete urllib
Para acceder a recursos de Internet Python nos proporciona en la Biblioteca estándar un paquete fundamental llamado urllib.
Si bien lo más común es que accedamos a las páginas web a través de un navegador web (Chrome, Firefox, Edge etc.) podemos también hacerlo mediante un programa codificado en Python.
El primer módulo que veremos del paquete 'urllib' se llama 'request' y tiene por objetivo permitir acceder a cualquier recurso alojado en Internet.
El primer ejemplo nos mostrará la facilidad que tenemos en Python para recuperar un archivo html localizado en Internet.
Lectura de una página HTML.
Recuperar la página html 'pagina1.html' que se encuentra localizada en:
http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html
Programa: ejercicio336.py
from urllib import request
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html")
datos=pagina.read()
print(datos)
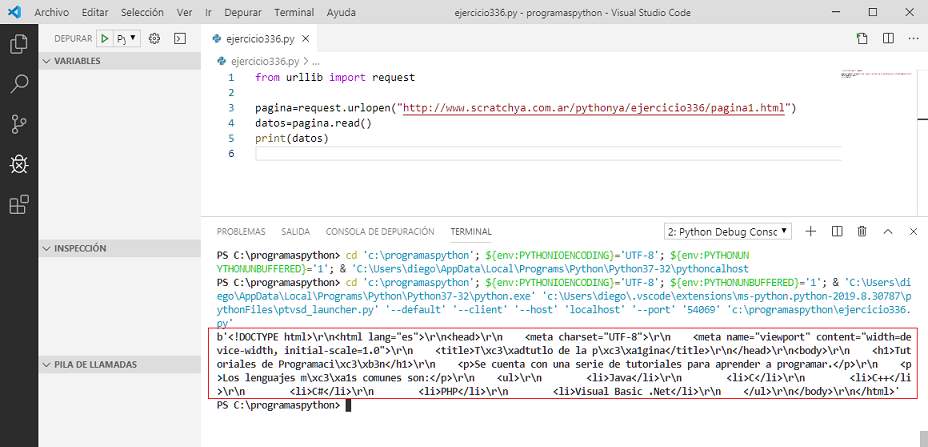
La ejecución del script nos muestra el contenido del archivo 'pagina1.html' que se encuentra en el servidor antes mencionado:
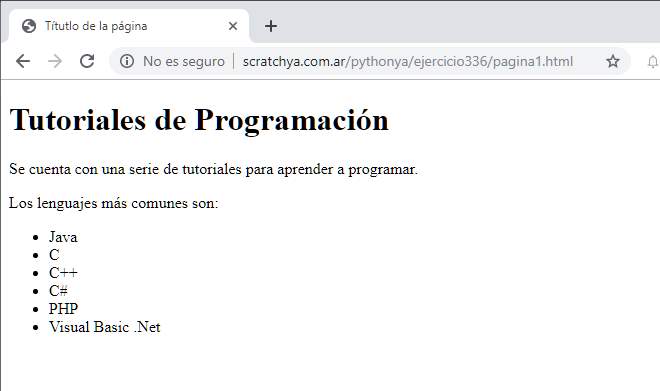
Un navegador web además de recuperar el contenido del archivo HTML como hemos hecho en Python, procede a interpretarlo y mostrarlo con el formato adecuado:
Lo primero que hacemos es importar el módulo 'request' que se encuentra en el paquete 'urllib':
from urllib import request
Mediante la función 'urlopen' recuperamos del servidor el recurso que le indicamos como parámetro:
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html")
La función 'urlopen' retorna la referencia de un objeto de la clase 'HTTPResponse' y se almacena en la variable 'pagina'.
Procedemos seguidamente a llamar al método 'read' que tiene por objetivo recuperar todos el contenido de la página HTML:
datos=pagina.read() print(datos)
Transformar a formato 'utf-8'
El método 'read' recupera los datos como un bloque de bytes, si vemos la imagen anterior donde imprimimos la variable 'datos' podemos comprobar que aparece entre comillas y antecedido por el caracter 'b':
b'<!DOCTYPE html>\r\n<html lang="es"> ........
Luego si queremos convertir el bloque de bytes a 'utf-8' debemos hacerlo llamando al método 'decode' indicando el formato respectivo:
Programa: ejercicio336.py
from urllib import request
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html")
datos=pagina.read()
datosutf8=datos.decode("utf-8")
print(datosutf8)
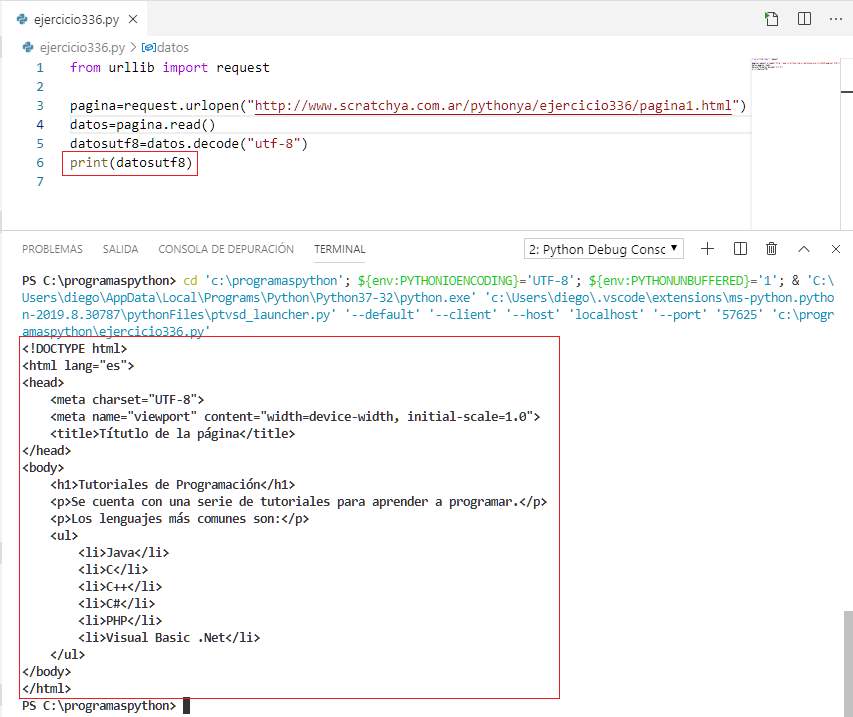
Si ejecutamos ahora nuevamente la aplicación podemos ver el contenido convertido a texto con formato 'utf-8' (formato de codificación de caracteres más común empleado en Internet para representar múltiples idiomas):
Lectura de una página HTML u otro recurso y posterior grabación del archivo en forma local.
Recuperar la página html 'pagina1.html' y el archivo 'imagen1.jpg' que se encuentran localizados en:
http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html http://www.scratchya.com.ar/pythonya/ejercicio336/imagen1.jpgluego grabar los dos archivos en forma local en el equipo donde se está ejecutando el script de Python.
Programa: ejercicio337.py
from urllib import request
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html")
datos=pagina.read()
archivo1=open("pagina1.html","wb")
archivo1.write(datos)
archivo1.close()
imagen=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/imagen1.jpg")
datos=imagen.read()
archivo2=open("imagen1.jpg","wb")
archivo2.write(datos)
archivo2.close()
Procedemos primero a importar el módulo 'request' del paquete 'ulrlib':
from urllib import request
Recuperamos del servidor el recurso 'pagina1.html' en formato binario:
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html")
datos=pagina.read()
Creamos un archivo binario en nuestro equipo con el nombre 'pagina1.html' y procedemos a almacenar el bloque de bytes recuperados del servidor:
archivo1=open("pagina1.html","wb")
archivo1.write(datos)
Cerramos el archivo que acabamos de crear llamando al método 'close':
archivo1.close()
Los mismos pasos damos para recuperar el archivo 'imagen1.jpg' y crear el archivo en nuestro equipo:
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/pagina1.html")
datos=pagina.read()
archivo1=open("pagina1.html","wb")
archivo1.write(datos)
archivo1.close()
Es decir no es importante el formato del archivo (html/jgp/gif/json etc.) para recuperarlo de un servidor de Internet.
Módulo 'error' del paquete 'urllib'.
Si el recurso no se encuentra en el servidor de internet o se genera cualquier otro tipo de error, podemos capturar la excepción 'HTTPError' del paquete 'urllib'
Confeccionaremos un script que intente recuperar una página HTML que no se encuentre en el servidor:
http://www.scratchya.com.ar/pythonya/ejercicio336/paginax.htmlluego capturaremos la excepción 'HTTPError'
Programa: ejercicio338.py
from urllib import request
from urllib import error
try:
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/paginax.html")
datos=pagina.read().decode("utf-8")
print(datos)
except error.HTTPError as err:
print(f"Código de respuesta HTTP devuelto por el servidor {err.code}")
print(f"No existe el recurso {err.filename}")
Lo primero que hacemos además de importar el módulo 'request', es importar el módulo 'error' también almacenado en el paquete 'urllib':
from urllib import request from urllib import error
Al método 'urlopen' lo debemos disponer dentro de un bloque try:
try:
pagina=request.urlopen("http://www.scratchya.com.ar/pythonya/ejercicio336/paginax.html")
datos=pagina.read().decode("utf-8")
print(datos)
El método 'urlopen' puede generar una excepción de tipo 'HTTPError':
except error.HTTPError as err:
print(f"Código de respuesta HTTP devuelto por el servidor {err.code}")
print(f"No existe el recurso {err.filename}")
Mostramos en el bloque except datos almacenados en la excepción elevada por el método 'urlopen':
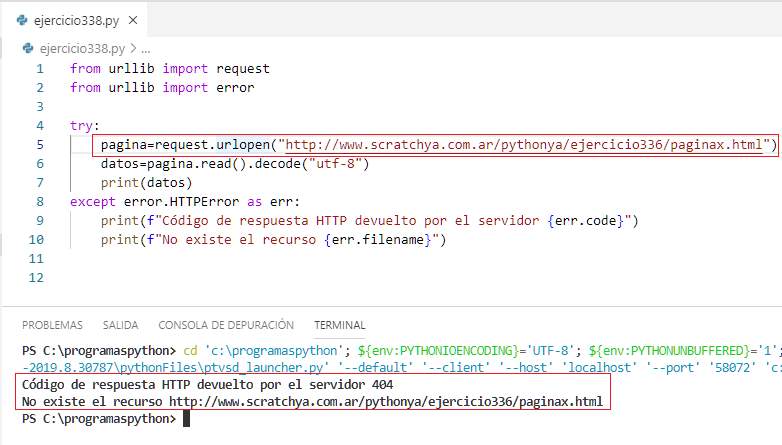
Como el archivo 'paignax.html' no existe luego se ejecuta el bloque except donde podemos consultar los datos almacenados en la excepción.
Problema propuesto
-
Confeccionar una aplicación visual con tkinter que permita ingresar en un control de tipo 'Entry' la URL de un sitio web y al presionar un botón recuperar los datos y mostrarlos en un control de tipo 'ScrolledText':
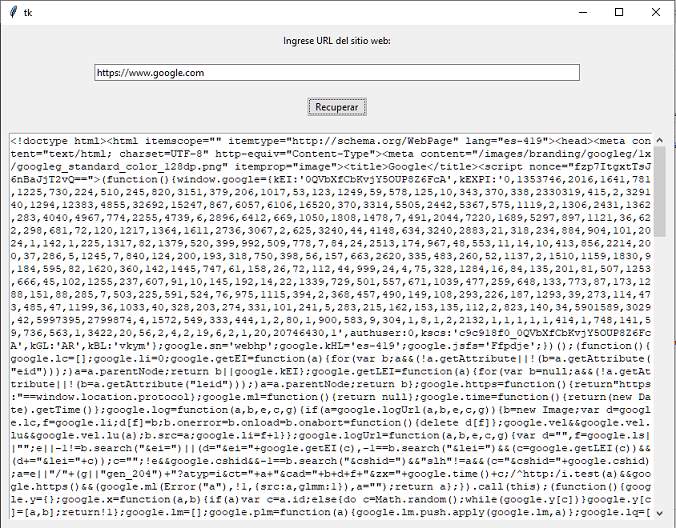
ejercicio339.py
import tkinter as tk
from tkinter import ttk
from tkinter import scrolledtext as st
from urllib import request
from urllib import error
from tkinter import messagebox as mb
class Aplicacion:
def __init__(self):
self.ventana1=tk.Tk()
self.label1=ttk.Label(text="Ingrese URL del sitio web:")
self.label1.grid(column=0, row=0, pady=10)
self.dato1=tk.StringVar()
self.entry1=ttk.Entry(self.ventana1, width=100, textvariable=self.dato1)
self.entry1.grid(column=0, row=1, pady=10)
self.boton1=ttk.Button(self.ventana1, text="Recuperar", command=self.recuperar)
self.boton1.grid(column=0, row=2, pady=10)
self.scrolledtext1=st.ScrolledText(self.ventana1, width=100, height=30)
self.scrolledtext1.grid(column=0,row=3, padx=10, pady=10)
self.ventana1.mainloop()
def recuperar(self):
try:
pagina=request.urlopen(self.dato1.get())
datos=pagina.read().decode("utf-8")
self.scrolledtext1.delete(1.0,tk.END)
self.scrolledtext1.insert(tk.INSERT,datos)
except error.HTTPError as err:
mb.showinfo("Problemas", "No se puede acceder a dicho recurso")
aplicacion1=Aplicacion()